ժ Ҫ �������һ���µĶ���������������ȡ�ķ����������������ÿ�����������ۺ���ֵ���˷����ܹ������������������÷������������ݼ�����ʵ���ݼ��Ͻ�����ʵ�顣ʵ��������omi�ܹ�ȷ�ظ�Ч���ڸ������ݼ��ϼ����������������
�ؼ��� ����ѡȡ���������������磻���������
1 ����
������Ϣ��ѧ�����Ŀ��ٷ�չ���ڹ�ҵ���ѧ�������Ÿ����Ӻ���Ķ������ģ���⡣�о���Ա���ֵ�����غ����������������֮��ģʽʶ���������ܽ���������ߡ��ɴˣ�������ȡ��Ϊ������Ԥ�����������ھ�������Ҫ�IJ���֮һ������������������ȡ�����������㣬��ǿϵͳ�Ŀɶ��ԣ��Լ����ϵͳ��Ԥ�����ܡ�
һ������������ѡ���������裺�������ۺ���ֵ�������Ӽ���Ѱ
[1]�����ۺ���Ҫ�ܷ�ӳ��������������������Ϣ��ƥ�����Ϣ���Լ����������ܱ仯����Ϣ�����������Ӽ���Ѱ������Ϊ�˱��ⷱ�ߵ�����©��Ѱ��һЩ�������ѧ���Ͽɵ���Ѱ�������㷺���ã����磺ǰ��ѡ����ɾ����˫����Ѱ�ȵ�
[2]��wwW.11665.com����ȫ��Ѱ���漴��Ѱ��ȣ�������˳�����Ѱ�������ܼ����ٵ�ִ�С�
�ڹ����������ݺ�������ݵĸ���ӳ�䷽�棬���ڶ��������(mlp)��Խ���ܣ����mlp���㷺�IJ��á����IJ���mlp����Ϊ����������չʾ��������ѡȡ�����ڸ������ݼ��ϵķ������ܡ�
2 ���Ż���Ϣ
����shannon��Ϣ���ۣ�һ���������c�IJ�ȷ���Կ�������h��c�������ơ����������������x��c��������
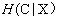
���Թ��Ƶ�����x��֪ʱ������c�IJ�ȷ���ԡ�������Ϣ
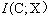
���Թ��Ʊ���c�ͱ���x��������ԡ��Ӷ���h��c�� ��
��
���������µĹ�ϵ
[3]��
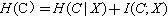
���ȼ���
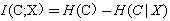
(1)
ѵ������ģ�͵�Ŀ������С����֪ѵ�����������������ݵIJ�ȷ���ԡ���
�Ƚϴ�����ζ��ѵ�����ݼ�x����������Ϣ�ܹ���Ч��Ԥ�����ǵ������ԣ��෴�أ���
�Ƚ�С������ζ��ѵ�����ݼ�x����������Ϣ���ܹ���Ч��Ԥ�����ǵ������ԡ����ԣ�ѵ���������Ĺ���Ӧ����һ������������ȣ���������������Ϣ
��
����������ѡȡ���ԣ���Ŀ���Ǵ�����ȫ��
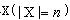
��ѡȡһ�����Ӽ�
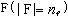
ʹ�û���Ϣ
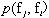
�����ܵĴ������������Ӽ�f�ܹ���Ч��Ԥ��ѵ�����ݵ������ԡ�Ҳ����˵������
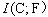
��f�Ӷ����ɵõ�
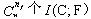
�����ǿ���ѡ������
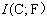
����Ӧ��f����Ϊ���ŵ�����������������ȫ��x��
Ȼ�������ϵ�����ֻ�ǿ��ǵ��������Ӽ�f��������c����������ԣ�fδ�س�Ϊ���ŵ���������������f��ÿ��������������c�����������ʱ�����ǵ����п��ܺ��м������Ի��������ص����������ظ�����������������Ӧ��������Щ�����������ʹ�ô������f��Ϊ�µ����ŵ���������
������
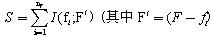
��
��ˣ��������Ժ���С������Ӧͬʱ������һ�����Ƕ���һ�����Ӧ�
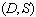
��d��s������������
���Ӷ�����ͬʱ�Ż�d��s��
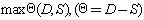
(2)
��ʵ���У����ǿ��Բ�ȡǰ���������Ѱ������������(2)���ҵ����ŵ����������������������Ѿ�����(m-1)��������f
m-1�����ڵ�������Ҫѡȡm
th������
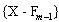
����һ���̿���ͨ�����()��ʵ�֡�Ҳ���Ż���ʽ��
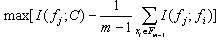
(3)
����

��
3 omi������ȡ�㷨
ͨ�����Ϸ��������ǽ�omi������ȡ�㷨������Ϊ���¹��̣�
��ʼ������f��Ϊ�ռ���xΪ��������������ȫ����
(1)�����������ԵĻ���Ϣ����ÿһ������
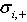
������
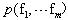
��
(2)ѡȡ��һ��������ѡ������f����Ӧ���Ļ���Ϣֵ
����������
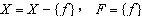
��
(3)�ݹ���㣺ѡ������f����Ӧ����omi���ۺ���������
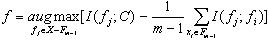
(4)���
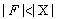
���ص���2��������f��Ϊ����������������������
��Ҫָ�����ǣ�ͨ���������������������ԵĻ���Ϣֵ��������ÿ��������������Ե��������������ǿ���֤���ġ����⣬omi���ۺ������Ա�����������ĵ��ܶȺ���������Ϣ�����磺����
��
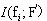
����ζ����Ҫ�ȼ���
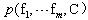
��
�����������ڸ�ά���ݼ���ʵ���У�����Ч��ȷ�ع��ơ���omi�У�ֻ�����
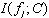
��
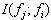
����ζ��ֻ���ȼ���
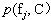
��
���ɡ�ͨ�������������parzen window��histogram�ȳ��õĵ�ά�ܶȺ������Ƶķ��������ơ�
4 ����������ȡ�㷨
����������ȡ�ķ������������Ϊ�����ࣺ����ʽ��Ƕ��ʽ������ʽ��ָ������ȡ���㷨���������ѵ���㷨�أ���Ƕ��ʽ��ָ������ȡ���㷨���������ѵ���㷨ֱ����ء�һ����ԣ�����ʽ�ķ�������ִ�ж�������Ч�ʸߣ�Ȼ��Ƕ��ʽ�ķ���ѡ���������������ɿ����Ǽ������dz����������omi����������������ѡȡ������ʱ��δ�õ��κη�������ѵ���㷨������omi���ڹ���ʽ������ѡȡ�����������ں��ĵ�ʵ�鲿�ֿ��Կ���omiѡȡ�������������д����Ե�Ƕ��ʽ����ѡȡ������Ҫ�á�
�����д����ԵĹ���ʽ����Ϊfisher score
[4]��fisher score����ͨ��ʽ(4)������ÿ�����������Բ�ͬ�����Ե������������Ӷ��ó���������������
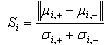
(4)
����
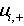
��
�ֱ���
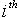
���������ڵ�һ��ľ�ֵ�ͷ����
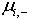
��
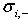
�ֱ���
���������ڵڶ���ľ�ֵ�ͷ����ʽ(4) ���Կ���ÿ��������������Ҫ��ֻ���ɾ�ֵ�ͷ���ı�ֵ�������������ڸ�ά�����ݼ��У�������ѡȡ��Ч�������ɿ���
���д����Ե�Ƕ��ʽ�����У�leave-one-out
[5]��maximum output information
[6]��leave-one-out����ÿɾ��һ����������ʱ������һ��validation���ݼ��ϵķ����������ʱ仯����������ʱ仯��Խϴ�����ƶϴ��������������Ҫ����֮��Բ���Ҫ���ɴˣ�Ҳ�ɵó�����������������������������maximum output information������mlp��������������ϣ�ͨ�����������Ϣ�����������������ڵ��Ȩֵ�Ĵ�С��ѡ��һ�����Ҫ���������������������������ظ����Ϲ�����ÿһ��������������������Ϊ���Ҫ�������������������Ϊ����Ҫ�������������Ӷ�Ҳ�ɵó�������������������ֵ��ע����ǣ�������Ƕ��ʽ������ѡȡ�ķ����ڵݹ�������������������Ҫ�̶��Ƕ���������ѵ��������������Ƕ��ʽ������ѡȡ��������Ч���ձ�ܵ͡�
5 ʵ����
5.1 �������ݼ�
����ѡȡ�������㷺���õ��������ݼ�monk��weston���ݼ���չ��omi������ȡ�㷨�ܹ���Ч�ؿɿ��ض������������������������������ݼ��Ľ��ܼ���1�������������ݼ��ķ���������3��mlp�����硣���ڲ��ڵ����Ŀ��5-fold crossvalidation�ķ�����ȷ����
��1 ���ݼ�����
���ݼ�����
monk
weston
ѵ������������
432
200
���Լ���������
124
9800
������������
6
10
mlp����ڵ����
5
6
monk1���ݼ����Դ�uci��վ�������ݿ����صõ�(http��//archive.ics.uci.edu/ml/)����֪6�����������������ԵĹ�ϵ������f
1=f
2�����ߣ�f
5=1�� ʱ���������ڵ�һ�࣬��֮���ڵڶ��ࡣ�ɴ˿ɼ���
�����ݼ�ֻ��ѡ����������1��2��5���ɡ���2�г�������������������Ҫ�̶Ƚ����������top1-top6����������Ϊ���룬��Ӧ�IJ����������ķ����������ͼ1�и�����
��2 monk���ݼ�������������
2
1
5
3
4
6
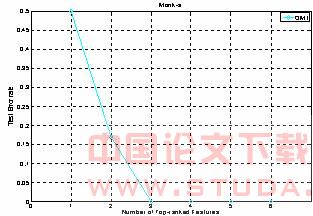
ͼ1 monk���Լ�������
���ǰ���weston
[5]�ķ���������weston���ݼ��������ݼ�����10��000��������ÿ����������10����������������ֻ��f
1,f
2������������صģ���������������ȫ�����Ƿ���n��0��20���������������f
1,f
2�ֱ����
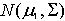
��
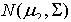
�ֲ����ڵ�һ���У�
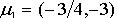
��
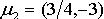
�����ڵڶ����У�
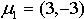
��
�������е�
�����������ݼ�ֻ��ѡ����������1��2���ɡ�Ϊ�˱����������ʼֵ�Ȳ�ȷ�����ص�Ӱ�죬��ʵ�鹲����30�Ρ�ͼ2�и�����top1-top10����������Ϊ���룬��30��ƽ���IJ��Լ���������ʡ���3�г�������������������Ҫ�̶����յĽ��������
��3 weston���ݼ�������������
1
2
10
7
8
4
5
3
9
6
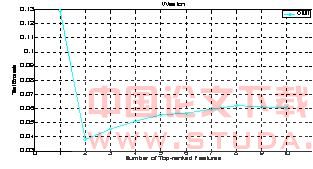
ͼ2 westonƽ�����Լ�������
�ɴ˿ɼ���omi����Ч�ؿɿ��ز�ȷ�ض���������������������
5.2 ��ʵ���ݼ�
moi��������ѡȡ������������ʵ���ݼ�heart��ionosphere��waveform+noise �Ͻ��в��ԡ������������ݼ��Ľ��ܼ���4��
��4 ���ݼ�����
���ݼ�����
heart
ionosphere
waveform noise
ѵ������������
170
200
400
���Լ���������
100
151
4600
������������
13
34
40
mlp����ڵ����
1
26
3
��3����������fisher score��leave-one-out��maximum output information��omi�����Ե���������������top1-topn����������Ϊ���룬��30��ƽ���IJ��Լ������������ͼ3-ͼ5�и�����ͬ��Ϊ�˱����������ʼֵ�Ȳ�ȷ�����ص�Ӱ�죬���еķ������������ݼ��Ϸֱ�����30�Ρ�
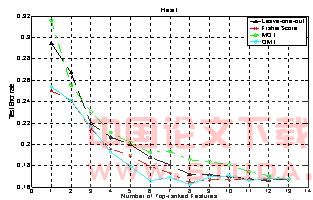
ͼ3 heartƽ�����Լ�������
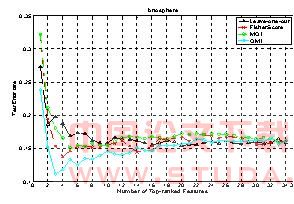
ͼ4 ionosphereƽ�����Լ�������
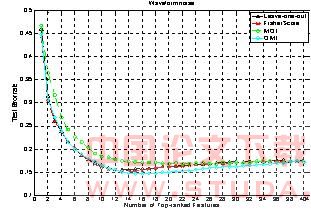
ͼ5 waveform noiseƽ�����Լ�������
��ͼ5��ʾ��omi�ķ����ó�������������Ҫ���������������������ܴ���ͼ��֪omi��ijЩtop���������Ĵ�����Ҫ����������������������ͨ��t-test�ķ������Եó����ַ�������Щtop���������Ĵ����ʾ�ֵ�ɽ��ƿ�������ȵġ����仰˵�����������ݼ��Ľ��������moi��ѡ����top��������������������������ѡȡ����ѡ����top����������
�������ٶȶ��ԣ�fisher score��죬omi��֮����leave-one-out��maximum output information����Ƕ��ʽ���������ԣ����DZ���������һ����������������ѵ��mlp�����磬���ԣ�����ʱ�������ӡ�
6 ����
����������һ�ֻ��ڻ���Ϣ���۵���������ѡȡ�ķ��������ھ����㹻����Ϣ����֧�֣���һ�µ�����������������۱�ʽ��Ҫ��������������Խ�ԡ����ȣ����������ŵػ�ӽ����ŵ�ѡ���û����������������������Σ�����������������ƿ����Լ��ɻ��ķ�ʽ��Ч���С���ڶ��������ڸ�ά���ݼ�����Ϊ��Ҫ����Ϊ������Ҫ�κ��˹��ĸ�Ԥ�������
�����ǵ�������ӵ���������ѡȡ�����������˶�����ܶȹ��ơ����������ʽ��������ѡȡ�ı��ʣ��˷������������еķ������㷨���ϣ���ִ�и���ģʽʶ��
���������ݼ�����ʵ���ݼ��Ľ���Ƚϣ�����omi����ѡȡ�����ܹ���������߷��ྫ�Ƚ�������ʱ�䡣�������������У����ӵ�������ṹʹ���ڸ�ά���ݼ��������Ч��ִ�С���omi����ѡȡ������Ч������ά���ݼ��в���ػ�����������������⽫�������������㷨�����ܡ�
�����
[1]a.l. blum and p.langley����selection of relevant features and examples in machine learning���� artifical intelligence��vol. 97��pp. 245�C271��1997
[2]vapnik��v.n.��statistical learning theory. new york�� wiley
[3]t.m.cover and j.a.thomas��elements of information theory. new york�� wiley��1991
[4]guyon.i.��and andre.e.����an introduction to variable and feature selection���� journal of machine learning research��vol. 3��1157-1182
[5]weston��j.��mukherjee��s.��chapelle��o.��pontil��m.��poggio��t.��and vapnik��v.n����feature selection for svms����advances in neural information processing systems.��vol.13��pp. 668�C674
[6] v.sindhwani��s.rakshit��d.deodhare��j.c.principle��and p.niyogi����feature selection in mlps and svms based on maximum output information���� ieee trans. neural networks��vol.15��no.4��pp. 937�C948��july. 2004