摘 要 作者开发的基于web的研究生学位信息管理系统具有数据录入、数据处理、信息查询、信息输出、数据导出等基本功能。介绍了系统体系结构以及开发的关键技术,包括基于窗体身份验证、基于角色的用户管理以及基于存储过程的分页显示技术等。
关键词 学位信息管理系统;身份验证;用户管理;分页显示
1 引言
研究生学位管理是研究生教育的一个重要环节,是一项涉及多学科知识,需多部门协调工作的管理系统工程。它主要完成数据录入、数据处理、信息输出和数据导出等工作。学位管理部门要求:可以从其它部门获取已有的学生信息,也可以手工录入学位信息;数据经过处理后以适当的形式输出相关文件或表格,如学位申请表、授予学位文件、授予学位名单、学位证明等,同时将处理后的数据按一定格式上报教育部。
针对上述需求,我们开发了基于web的研究生学位管理信息系统。该系统采用asp.net2.0开发平台、c#语言、sql server 2000数据库管理系统,在基于intranet/intranet的校园网环境下运行。wwW.11665.com
2 系统设计
本系统采用三层b/s体系结构,如图1所示,其中:
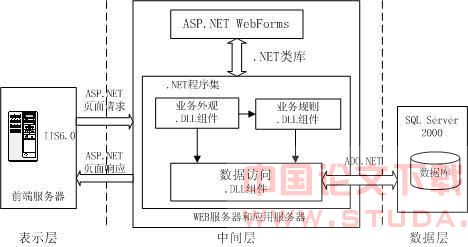
图1 系统体系结构图
表示层:相当于用户界面,为客户端提供对整个应用程序的访问。在本系统中表示层由asp.net web窗体和代码隐藏文件组成。在.aspx文件中只有html代码和服务器控件,在页面程序代码文件(.cs文件)中调用.dll组件中的数据库操作方法,返回满足条件的结果。
中间层:是整个系统的核心部分,担当主要的应用处理,包括处理表示层的http请求以及对数据库的访问。
在设计系统时,我们把应用程序中的业务逻辑放在中间层应用服务器上,这样业务逻辑和用户界面分开。如果要修改应用程序代码,只须对应用服务器进行修改,而不用修改成千上万的客户端应用程序。同时由于asp.net只支持面向对象,组件也可以看作类,因此可以在web项目中添加对数据库操作的组件,并将其编译为.dll,这样就把数据库的操作过程封装起来,便于代码的安全管理和维护。因此,我们把中间层进一步分解为业务外观、业务规则、数据访问等层进行处理,并且把它们封装在了独立的.dll组件中。
其中,业务外观层用作隔离层,它将用户界面与各种业务功能的实现隔离开来,它除了为表示层提供服务,还可以访问业务规则和数据访问层,是系统的公共入口点。业务规则层包含了各种业务规则和逻辑的实现。数据访问层为业务外观层和业务规则层提供数据服务,其中包含了各种数据访问的类。
数据层:位于底层,以ado.net为接口,sql server2000为后台,主要处理应用层对数据的请求。
系统运行时,客户端浏览器发出对页面的访问请求,访问表示层各aspx文件,再将各请求事件发送到业务外观层,业务外观层根据需要访问业务规则层或数据访问层。而业务规则层只能访问数据访问层,数据访问层通过ado.net访问数据层的存储过程以达到对数据库的操作。由于整个系统由相互交互的各层实现,因此可以实现系统的分布式部署,以达到分布式应用来减轻各层的压力。
由于客户端向服务器请求页面时,其复杂的逻辑处理在服务器端进行,在客户端只能看到该网页的最终表现和html,而不能看到该网页的程序逻辑,这样可以有效地保护程序代码的安全。
图1对应的研究生学位信息管理软件模块结构如图2所示。
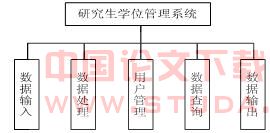
图2 学位系统功能模块图
其中,各模块实现的功能如下:
(1)数据导入:辅助学位办工作人员从其它部门(招生办、培养科)导入学生已有的基本信息,包括学籍信息和培养信息。
(2)数据录入:辅助学位办工作人员通过研究生部局域网,以及研究生通过互联网录入相关信息。
(3)数据处理:实现学位证书号码自动生成、数据转存数据维护等操作。
(4)用户管理:实现各种登录用户的角色、权限管理以及密码修改。
(5)数据查询:实现从数据库查找相关学生记录,并按一定格式显示和打印。
(6)数据输出:实现学位申请表的打印、学位信息导入、上报库dbf表等功能。
3 系统实现
1) asp.net中的安全机制
学位系统采用asp.net安全架构中的表单验证方式实现用户登录。使用表单身份验证时,通过指定的登录页面收集用户的凭证信息,如果未验证身份的用户试图访问受保护的文件或资源(其中,url授权拒绝用户访问)将被重新定向到该登录页面,用户在此处尝试通过身份验证。用户提供凭据并提交该窗体,如果应用程序对请求进行身份验证,系统会发出一个cookie,其中包含用于重新获取标识的凭据或密钥。随后发出的请求在请求头中具有该cookie,asp.net事件处理程序使用应用程序开发人员指定的任何验证方法对这些请求进行身份验证和授权。其验证流程如图3所示。
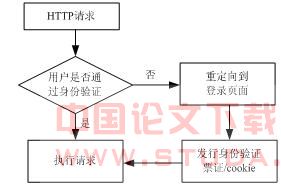
图3 基于窗体的身份验证流程
基于窗体的身份验证开发步骤如下:
(1) 将iis配置为使用匿名访问。
(2) 将 asp.net 配置为使用表单身份验证。在web.config文件中配置authentication元素的属性,设置为身份验证模式。
<authentication mode="forms">
<forms name=".aspxauth" protection="encryption" timeout="15" loginurl="login.aspx" />
</authentication>
(3) 检索数据存储验证用户,从自定义数据存储中检索角色列表(不是基于角色可不用)。
(4) 使用formsauthenticationticket创建一个cookie并回发到客户端,并存储角色到票中。
formsauthentication.setauthcookie(username,true | false)
httpcontext.current.response.cookies[formsauthentication.formscookiename].expires=datetime.now.adddays(1) //cookies保存时间
如果需要存储角色,采用:
formsauthenticationticket authticket = new forms authenticationticket(
1, // 版本号,设置为1
txtusername.text, // 用户标示
datetime.now, // cookie的发出时间, 设置为 datetime.now
datetime.now.addminutes(20),// cookie的有效时间
false, // 是否持久性
roles ); //roles为存储的用逗号分割的角色串
string encryptedticket = formsauthentication. encrypt (authticket); //把身份验证票加密
//设置验证票cookie,第一个参数为cookie的名字,第二个参数为cookie的值也就是加密后的票
httpcookie authcookie =
new httpcookie(formsauthentication.formscookiename,
encryptedticket);
response.cookies.add(authcookie); //把cookie加进response对象发生到客户端
(5)在global.asax内的application_authenticaterequest事件中处理程序中(global.asax)中,使用票创建iprincipal对象并存在httpcontext.user中。
httpcookie authcookie = context.request.cookies [forms authentication.formscookiename];
formsauthenticationticket authticket = forms authentication. decrypt(authcookie.value);//解密
string[] roles = authticket.userdata.split(new char[]{','});//根据存入时的格式分解角色
context.user = new genericprincipal(context.user. identi ty, roles);//存入httpcontext.user
2) 基于角色的用户管理
基于角色的访问控制已经相当成熟,作为策略中立的鉴别和授权机制,通过角色的继承和职责分离等控制约束条件可以实现多种控制策略。基于角色的访问控制引入角色这个中介,安全管理人员根据需要定义各种角色,并设置合适的访问权限,而用户根据其职责被指派为不同的角色。由于实现了用户与访问权限的逻辑分离,基于角色的策略极大地方便了权限管理,而且对实际应用环境的访问控制需求的描述更自然,而对一个组织来说,其行为特征和功能是比较稳定的,因此其角色是比较稳定的。由于角色/权限之间的变化比角色/用户关系之间的变化相对要慢得多。
本学位管理系统包含了多种数据操作功能,并且拥有不同种类的多个用户,从总体上考虑可以分为管理员、教师(普通教师、研究生秘书)和研究生(硕士、博士、专业硕士等)。不同类别的用户对系统功能的使用权限是不同的,因此要求系统提供一种对多用户的权限管理,以确保具有权限的用户能够获取或处理数据和信息,禁止所有未授权用户操作数据。针对系统的这一特点,我们在开发过程中,采用了两级控制机制分别对页面资源和数据进行控制。在用户成功登录系统后根据用户角色所具有的权限动态生成菜单页面,从而限制了用户对未授权页面的访问;在用户访问同一页面时,对于不同的用户所获取的数据信息是不一样的。例如,对于不同学院的研究生秘书进入系统后,他们只能操作所在学院的学生数据。
在研究生学位管理系统中,我们把所有系统用户的角色信息保存在数据库的用户表中。其次,将系统中所有的功能模块及其子功能访问接口的访问权限信息都存放在数据库中的访问权限表中。
当用户登录学位管理系统时,权限管理的系统流程如图4所示。
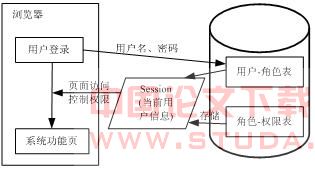
图4 权限管理的系统流程
3) 基于存储过程分页显示技术
显示数据查询的结果时,为了缩短页面数据的显示时间,我们利用分页的方法来显示查询结果。传统的数据分页方法是ado 纪录集分页法,也就是利用ado自带的分页功能(利用游标)来实现分页。但这种分页方法仅适用于较小数据量的情形,因为游标本身有缺点:游标是存放在内存中,很费内存。游标一经建立,就将相关的记录锁住,直到取消游标。
对于数据量大的数据源而言,分页检索时,如果按照传统的每次都加载整个数据源的方法是非常浪费资源的。因此在分页的时候可以检索当前页面所需数据,而非检索所有的数据,然后单步执行当前行,这就是我们所说的基于存储过程的分页显示技术。最早较好地实现这种根据页面大小和页码来提取数据的方法是“俄罗斯存储过程”。这个存储过程用了游标,由于游标的局限性,该方法没有得到很好的应用。
事实上,在查询和提取超大容量的数据集时,影响数据库响应时间的最大因素不是数据查找,而是物理的i/0操作。例如我们取出学科名为计算机应用技术的前十名学生信息:
select top 10 * from (
select top 10000 xh,xm,hsxwrq from xueweixinxi where xkm='计算机应用技术'
order by xh desc) as a order by xh asc
从理论上讲,整条查询语句的执行时间应该比子句的执行时间长,但事实相反。因为,子句执行后返回的是10000条记录,而整条语句仅返回10条语句,所以影响数据库响应时间最大的因素是物理i/o操作。而限制物理i/o操作此处的最有效方法之一就是使用top关键词了。top关键词是sql server中经过系统优化过的一个用来提取前几条或前几个百分比数据的词。由于使用top执行查询操作的效率很高。因此我们可以考虑使用top关键词来进行分页查找,由此可以得到如下分页算法:
select top 页大小 * from table where (id not in
(select top 页大小*页数 id from 表 order by id)) order by id
和游标存储过程比起来,该存储过程在速度上有了很大的提高,而且每次查询只需要取出当前页面所需的数据,不需要加载整个数据源,是一个非常优秀的分页存储过程。但是在该存储过程中,使用了not in关键字进行数据读取。sql中的关键词in不符合sarg, sarg是用于限制搜索的一个操作,它通常是指一个特定的匹配,一个值的范围内的匹配或者两个以上条件的and连接。形式如下:
列名 操作符 <常数 或 变量> 或 <常数 或 变量> 操作符列名
如果一个表达式不能满足sarg的形式,那它就无法限制搜索的范围了,也就是sql server必须对每一行都判断它是否满足where子句中的所有条件。因此在该分页存储过程中,not in操作会扫描全表,因此在执行速度上依然不是很理想。
分页优化的最终目的就是避免产生过大的记录集,使用top 可实现对数据量的控制,因此在分页算法中,影响查询速度的关键因素有两点:top和not in。top可以提高查询速度,而not in会减慢查询速度,所以要提高整个分页算法的速度,就要使用其他方法替换not in。sql中可以通过max(字段)或min(字段)来提取某个字段中的最大或最小值,所以如果某个字段值不重复,那么就可以利用这些不重复字段的max或min值作为分页算法中分页的参照物。因此我们可以用操作符“>”或“<”使查询语句符合sarg形式,于是可以得出如下分页方案:
select top 页大小 from table
where (id > (select max(id) from
(select top ((页码-1)*页大小) id from table order by id) as t)) order by id
其中id是数据库表的主键。如果加上索引,查询效率会有很大的提高。
表1列出了对有着10万以上数据的学位历史表,在以sid(sid是主键,但并不是聚集索引)为排序列,提取xh,xm,hsxwrq字段,分别以第1、10、100、1000、1万页为例,测试以上两种分页方案的执行速度:(单位:毫秒)
表1 两种分页方案执行速度对比
1
10
100
1000
1万
方案一
30
16
720
470
4500
方案二
76
63
130
250
140
从表1中,我们可以看出,两种存储过程在执行1000页以下的分页命令时,都是可以信任的,速度都很好。但第一种方案在执行分页1万页以上后速度开始降了下来,而第二种方案却始终没有大的变化,在大数据量的情况下,特别是在查询最后几页的时候,查询时间一般不会超过9秒,非常适用于大容量数据库的查询。
4 结束语
本文介绍的基于web的研究生学位管理信息系统已经投入实际运行中。实践证明,本系统使用方便,易于管理,安全性高、可移植性好,有效地提高了研究生学位管理工作的自动化水平与工作效率,得到用户的好评。
参考文献
[1] 陈伟鹤,殷新春等. 基于任务和角色的双重web访问控制模型[j]. 计算机研究与发展,2004,41(9):1466-1473
[2] 赵燕飞,朱飞,孙玉星. 一种基于web的分布式应用程序框架的构建技术[j]. 计算机工程与应用 2004,36(36):168-170
[3] 张晓辉,王培康. 大型信息系统用户权限管理[j]. 计算机应用. 2000, 20(11):35-36