[摘 要] 本文描述了一种新的基于关键词组合模式的文本向量空间表示模型,相对于只使用文本中词语的频率的文本向量空间模型,这种新的模型在可以计算的前提下,使用了词语之间的相对位置信息,从而可以解决部分词语向量空间模型表示的不足。本文讨论了使用这种模型的自动文本分类系统,包括分类系统的结构、特征提取、文本相似度计算公式,并给出了评估方法。
[关键词] 关键词组合 向量空间 自动分类 分类算法
近年来,以文本格式存储的海量信息出现在internet、数字化图书馆及公司的intranet上,如何从这些浩瀚的文本中发现有价值的信息是信息处理领域的重要目标,而文本自动分类系统能够在给定的分类模型下,根据文本的内容自动对文本分门别类,从而更好地帮助人们组织及挖掘文本信息,因此得到日益广泛的关注,成为信息处理领域最重要的研究方向之一。
一、自动分类的种类和作用
自动分类就是用计算机系统代替人工对文献等对象进行分类,一般包括自动聚类和自动归类。自动聚类和自动归类的主要区别就是自动聚类不需要事先定义好分类体系,而自动归类则需要确定好类别体系,并且要为每个类别提供一批预先分好的对象作为训练文集,分类系统先通过训练文集学习分类知识,在实际分类时,再根据学习到的分类知识为需要分类的文献确定一个或者多个类别。本文中所指的自动分类是指对网页的自动分类,包括网页的自动归类和自动聚类。
目前搜索引擎提供两种信息查询方式:分类浏览和关键词检索。分类浏览一般是基于网站分类目录。wwW.11665.COm关键词检索的对象不是网站,而是符合条件的网页。关键词检索信息量大、更新及时、不需要人工干预。
二、问题描述
1.系统任务
简单地说,文本分类系统的任务是:在给定的分类体系下,根据文本的内容自动地确定文本关联的类别。从数学角度来看,文本分类是一个映射的过程,它将未标明类别的文本映射到已有的类别中,该映射可以是一一映射,也可以是一对多的映射,因为通常一篇文本可以同多个类别相关联。用数学公式表示如下:

文本分类的映射规则是系统根据已经掌握的每类若干样本的数据信息,总结出分类的规律性而建立的判别公式和判别规则。然后在遇到新文本时,根据总结出的判别规则,确定文本相关的类别。
2.评估方法
我们使用评估文本分类系统的两个指标:准确率和查全率。准确率是所有判断的文本中与人工分类结果吻合的文本所占的比率。其数学公式表示如下:

;查全率是人工分类结果应有的文本中分类系统吻合的文本所占的比率,其数学公式表示如下:
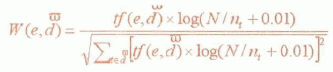
;准确率和查全率反映了分类质量的两个不同方面,两者必须综合考虑,不可偏废。
3.词语向量空间模型的文本表示
目前,在信息处理方向上,文本的表示主要采用向量空间模型 (vsm)。向量空间模型的基本思想是以向量来表示文本:(w1,w2,w3……wn),其中wi为第i个特征项的权重,那么选取什么作为特征项呢,一般可以选择字、词或词组,根据实验结果,普遍认为选取词作为特征项要优于字和词组,因此,要将文本表示为向量空间中的一个向量,就首先要将文本分词,由这些词作为向量的维数来表示文本。词频分为绝对词频和相对词频,绝对词频,即使用词在文本中出现的频率表示文本,相对词频为归一化的词频,其计算方法主要运用tf~idf公式,目前存在多种tf~idf公式,一种比较普遍的tf~idf公式为:;其中 ,为词t在文本中
,为词t在文本中 的权重,而
的权重,而 为词t在文本中的词频,n为训练文本的总数,nt为训练文本集中出现t的文本数,分母为归一化因子。
为词t在文本中的词频,n为训练文本的总数,nt为训练文本集中出现t的文本数,分母为归一化因子。
4.词语向量空间模型的训练方法和分类算法
训练方法和分类算法是分类系统的核心部分,目前存在多种基于向量空间模型的训练算法和分类算法,例如,支持向量机算法、神经网络方法,最大平均熵方法,最近 k 邻居方法和贝叶斯方法等等。一般相似度定义公式为: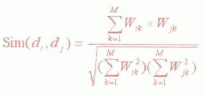 ;其中,di,dj为不同的文本,m为特征向量的维数,wk为向量的第k维。
;其中,di,dj为不同的文本,m为特征向量的维数,wk为向量的第k维。
三、关键词组合向量空间的文本表示模型
关键词组合是大多数搜索引擎使用的查询语言。我们这里定义的关键词组合(keyword expression)为:
keyword expression= keyword [and keyword] *
例如keyword expression =“大海”and “海鸥”表示如果文本中同时出现“大海”和“海鸥”,则这个文档满足关键词表达式。
定义p为可能关注的关键词集合为p,|p|为关键词的个数。对于一般的分类系统|p|一般为10万左右。pi为其中的一个关键词。关键词可以是一个有稳定的词语也可以是一个短语。
定义e表示可能关注的关键词集合。 |p|为关键词组合的个数. ei是其中的一个组合。同时保证出现在ei的关键词一定在p中。定义d表示全部文档集合。|d|为的文档个数.
是其中的一个文档。定义l表示一个表达式必须出现在多少连续的句子中。一般定义为3个句子。则定义文档
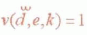
当且仅当在文本dk..k+l中出现了关键词组合e的全部关键词。定义

。则
表示表达式出现在文档的中的频率。类似向量空间模型,我们定义表达式的权重:

;其中
,为词e在文本中的
权重,n为训练文本的总数,nt为训练文本集中出现t的文本数,分母为归一化因子。
同理我们可以定义文本的相似度
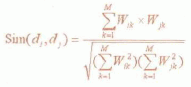
:;其中,di,dj为不同的文本,m为特征向量的维数,wk为向量的第k维。计算由于对于存在

的多关键词匹配算法,所以对关键词集合p可以在
计算出关键词序列q。使用自动机算法可以在o(|q|)时间内计算出全部出现的关键词集合。
四、特征词的提取
使用特征词的向量空间来表示文档时,直接使用构成文档的词条作为向量空间的维度,会使相应的词条向量矩阵非常稀疏和巨大,而且存在着大量对文档的描述和区分不相关或影响很小的词条维度,这会造成对文档语义描述的混淆和模糊。为了提高分类算法的效率和准确度,有必要对构成文档的词条进行特征词的提取和筛选,即对词条向量空间进行降维处理。
特征词提取有多种算法,大致可分为两种:一种是在现有的词条中从统计的角度选择对文档语义表达较好的词条,如ig (information gain),df (document frequency),χ2-statistic等特征词选取算法;还有一种是从现有词条中抽提和构造可以表达文档的隐含语义的特征,作为向量空间的维度,如隐含语义检索(latent semantic indexing, lsi)。lsi的核心操作是对词条文档矩阵进行截断的svd (singular value decomposition)分解,从而可以得到原词条文档矩阵在最小二乘意义上的最好近似。lsi可以在降维的同时,抽取文档的隐含语义,使得生成的文档向量可以较好地表达文档的语义。词条的权重算法对lsi的效果有一定的影响,据分析,联合使用平方根对数(square root-log,局部权重)-熵(entropy,全局权重)-余弦标准化(cosine normalization,归一化参数)来计算词条权重的效果比较好。
参考文献:
[1]朱华宇 孙正兴:一个基于向量空间模型的中文文本自动分类系统[j].计算机工程,2001,27(2):15~17
[2]秦 进 陈笑蓉 汪维家 陆汝占:文本分类中的特征抽取[j].计算机应用,2003,2(2):45
[3]庞剑锋 卜东波 白 硕:基于向量空间模型的文本自动分类系统的研究与实现.计算机应用研究, 2001(9)
[4]钟敏娟等:基于分类和关键词组抽取的信息检索算法[j].系统仿真学报,2004,(16)
[5]晋耀红 苗传江:一个基于语境框架的文本特征提取算法.计算机研究与发展,2004,vol.41,no.4:582~586