摘 要 通过详细分析试卷的各项约束条件,建立了一个以知识点、难度系数、区分度等为核心属性的自动组卷数学模型,并利用改进的遗传算法实现了自动组卷。
关键词 自动组卷;数学模型;遗传算法
自动组卷就是根据用户的要求,采用一定的算法自动地从试题库中抽取一定数量的试题组成试卷。自动组卷算法的好坏直接影响到试卷的质量,如何从试题库中选出试题组成符合用户要求的试卷,并使组卷具有较高的效率和成功率是当前研究的热门课题。现有的自动组卷算法一般有三种:随机选取法、回溯试探法和遗传算法。遗传算法是一种新发展起来的并行优化算法,它很适合解决自动组卷问题。
1 试题核心属性的确定
在自动组卷系统中,一些试题库设置了试题的各类属性,如章节、层次、要求、题型、难度系数、难度级别、各章节分值等属性,其实过多的属性会增加实际组卷的难度,降低效率。以教育学理论为指导,选择以下属性作为试题的核心属性。
(1) 题号。Www.11665.cOm试题的编号,用来唯一标识试题。
(2) 题型。试题的类型。
(3) 知识点。某道题属于某门课程的哪个知识点,知识点的设置不以章节为依据,从而可以避免教材的不同对组卷造成影响。
(4) 难度系数。难度系数
[1]是表示某一试题的难易程度,通常用未通过率来表示,即一次考试中未答对某道试题的考生数在其总体中所占的比例。一般来说,难度系数值为0.5时,是中等难度,如果小于0.3试题太简单,如果大于0.7试题太难,对考生都会做或都不会做(难度系数为0或为1)的试题,属于无意义的试题,必须淘汰。
(5) 区分度。区分度
[2]是指某道题对不同水平考生加以区分的能力。区分度高的试题,对学生水平有较好的鉴别力。区分度的计算公式为:
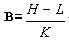
其中,b表示试题的区分度,h表示样本中高分组在某题上所得的平均分,l表示样本中低分组在某题上所得的平均分,k表示某题满分。高分组和低分组一般各占样本的25%~30%,最好取27%。一般来说,试题的区分度在0.4以上就被认为是很好的。在0.3~0.39之间,认为良好;在0.2~0.29之间,认为可以;在0.19以下,认为差,必须淘汰或加以修改。对在校学生的达标考试,试卷的区分度不宜太高,因为它不是选拔性质的考试。但也不能过低,否则对学生的鉴别效果差,不能很好的达到考试的目的。一般区分度控制在0.2~0.3之间为宜。
(6) 分值。某小题的分数。
(7) 答题时间。完成某题估计所需的时间。
2 自动组卷数学模型的建立
自动组卷中决定一道试题,其实就是决定一个包含题号、题型、知识点、难度系数、区分度、分值、答题时间的七维向量(a
1,a
2,a
3,
a4,a
5,a
6,a
7)。假设一套试卷中包含n道试题,一套试卷就决定了一个n×7的矩阵
s:

这就是问题求解中的目标矩阵,其中a
i1 、a
i2、 a
i3 、a
i4、a
i5、 a
i6 、a
i7分别表示试卷中第i道题的题号、题型、知识点、难度系数、区分度、分值、答题时间。从矩阵
s可以看出组卷问题是一个多重约束目标的问题求解,且目标状态不是唯一的。
在实际组卷时,用户会对试卷提出多方面的要求,用户的每一个要求对应试卷的一个约束条件。要组成一份符合要求的、高质量的试卷,目标矩阵的分布要满足以下试卷约束条件。
(1) 试卷中包含的题型以及每种题型的题量要与用户的设置相符。
k种题型的题量=
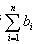
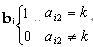
(2) 试卷中包含知识点即考核知识点以及各考核知识点所占分数的比例要与用户设置相符。
k种考核知识点所占分数=
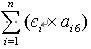
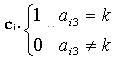
(3) 试卷的难度系数要满足用户的要求,试卷的难度系数一般用试卷中每道试题的难度系数的加权平均来计算。
即:试卷的难度系数=
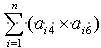
/总分
(4) 试卷的区分度要满足用户的要求,试卷的区分度一般用试卷中每道试题的区分度的加权平均来计算。
即:试卷的区分度=
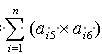
/总分
(5) 试卷的总分要与设置相符。
即:试卷的总分=
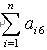
(6) 试卷的总答题时间要与用户设置相符。
即:试卷的总答题时间=
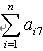
在实际组卷时,试卷的总分、考核知识点、各题型每小题分值、试卷中包含的题型、各题型的题量都应该是精确达到的。试卷中各考核知识点所占的分数、试卷的难度系数、区分度和试卷的总答题时间这四个约束条件可以存在一定的误差。误差的大小由用户的期望值和各约束条件的重要性决定。在实际应用中,各约束条件的重要性是不同的,因此,目标函数就取各项误差的加权和。目标函数f可以表示为:
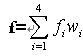
为了不至于各项误差相互抵消,实际值与用户要求值的误差都取绝对值。其中,试卷中各考核知识点所占的分数和试卷的总答题时间这两项的误差为实际值与用户要求值的误差绝对值与用户要求值的比,试卷的难度系数和区分度这两项的误差为实际值与用户要求值的误差的绝对值。w
i表示第i个约束条件的权值,w
i通常由专家经验或试验给出,0≤w
i
≤1,
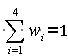
。由上式可知,目标函数
f的值越小,即误差
越小,问题的解越优,即生成的试卷越接近用户的需求。
3 遗传算法
遗传算法
[3,4,5]是以适应度函数(或目标函数)为依据,通过对群体中的个体进行遗传操作实现群体内个体结构重组的迭代处理过程。在这一过程中,群体中的个体一代一代地得以优化,并逐渐地逼近最优解,最终获得最优解。传统遗传算法的主要步骤包括初始染色体群体生成、适应度评估和检测、选择操作、交叉操作和变异操作。传统遗传算法流程图如图1所示(其中t为进化代数,t0为最大进化代数)。
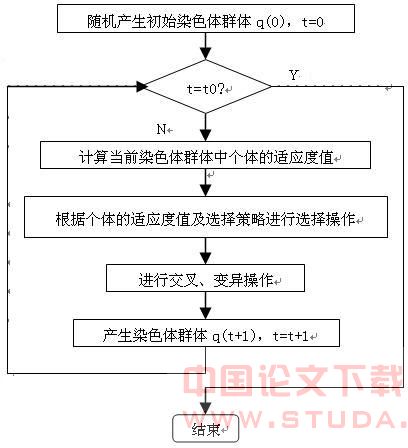
图1 传统遗传算法流程图
4 基于改进遗传算法的自动组卷
传统的遗传算法采用二进制编码,用1表示某题被选中,0表示某题没有被选中,这种编码非常简单,但在进行交叉和变异操作时,各题型的题量很难控制,而且当试题库题量很大时编码很长。传统的遗传算法以进化代数等于最大进化代数作为终止条件,但是在实际组卷过程中并不知道种群进化到第几代就能得到试卷的最优组合。因此用遗传算法实现自动组卷时,要对传统遗传算法进行一些改进。
4.1 改进的遗传算法
4.1.1 染色体编码
通过对编码的大量分析,提出了一种分段实数编码机制,首先将染色体分成若干段,每一段对应一种题型,组成试卷的各道试题题号直接映射为基因,编码时将同一题型的试题放在同一段,同一段内题号各不相同。以题号编码的方法所表达的意义清楚、明确、不需解码,从而可以提高算法性能,提高运算效率。而且交叉和变异操作都在各段内部进行,因此可以保证组卷过程中各题型题量的正确匹配。
4.1.2 适应度函数设计
遗传算法在进化搜索中仅以适应度函数为依据,利用种群中每个个体的适应度值来进行搜索。因此,适应度函数的选择至关重要,一般而言,适应度函数是由目标函数变换而成的。上面提出的自动组卷模型是最小化问题,采用如下方法可将目标函数f转换成适应度函数f。
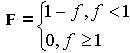
由上式可知,f的取值范围为0~1,适应度函数f的值越大,说明个体越好,个体越接近问题的最优解。
4.1.3 初始化染色体群体
随机生成初始染色体群体,在初始染色体群体中,染色体的长度为n,群体的大小为m,m太小时,难以求出最优解,太大时则增长收敛时间。群体的大小一般根据需要,按经验或试验给出,一般m=30~160。
4.1.4 遗传算子
(1) 选择算子
在遗传操作中,为了保留较优的个体,以概率1完全地复制每一代群体中按适应度值从大到小依次排列的前面2个个体。为了保持群体大小不变,同时删除适应度排列的后面的2个个体。然后从排列在前面的m-2个个体中随机抽取p(p≤m-2)个个体进行交叉和变异操作。这种选择策略使得适应度小的个体也有可能被选中,这样有助于增加下一代群体的多样性。
(2) 交叉算子
在遗传操作中,采用了分段的思想,交叉的时候按题型段进行交叉,因此交叉后不存在段内试题重复的问题,也不会改变每种题型的题量。交叉概率p
c太小时难以向前搜索,太大时则容易破坏高适应度的结构。一般p
c=0.4~0.6。
(3)变异算子
在遗传操作中,变异在染色体的题型段内进行。变异概率p
m太小时难以产生新的基因结构,太大时使遗传算法成了单纯的随机搜索。一般p
m=0.01~0.2。
4.1.5 终止条件
在改进的遗传算法中,设置了期望适应度值,把每一代计算出来的最高适应度个体的适应度值与期望适应度值相比较,当适应度最高的个体的适应度值大于或等于期望适应度值时则停止进化,否则继续进行遗传操作、计算适应度值、反复迭代直到组卷成功。
4.2 主要算法描述
基于改进遗传算法的自动组卷的主要算法描述如算法1所示。
算法1:
int gjga(p
c,p
m,m,f0)
{
t=0;
initialize(p(t));//随机产生初始染色体群体
计算初始染色体群体的适应度值;
while (maxf<f0) //当适应度最高的染色体的适应度值小于期望适应度值时
{
selection(p(t));//选择操作
crossover(p(t));//交叉操作
mutation(p(t));//变异操作
得到下一代染色体群体q(t+1),计算下一代染色体群体的适应度值;
t++;
}
输出当前染色体群体中适应度最高的染色体;
}
4.3 遗传算法复杂度分析
在遗传算法中,绝大部分处理都集中在适应度的计算上,因此可以用计算个体适应度操作的时间复杂度作为算法的时间量度。遗传算法的时间复杂度为o(t*m*n)。因为试题库中的题量一般都很大,所以改进后的遗传算法的时间复杂度一般要比传统遗传算法的时间复杂度小。遗传算法的空间复杂度可以用初始染色体群体所占的空间来衡量,遗传算法的空间复杂度为o(m*n)。因为改进后的遗传算法的染色体的长度远比传统遗传算法的染色体的长度小,所以改进后的遗传算法的空间复杂度远比传统遗传算法空间复杂度小。
5 结论
算法的改进往往不能顾及问题每一个方面,如果算法设计的核心是提高解的精度,则算法可能在搜索范围和搜索精度上花去更多的时间,如果算法的设计主要在于尽快收敛,得到结果,则在解的精度上考虑很少,算法往往侧重于减少进化代数。改进后的遗传算法使生成试卷的质量得到了保证,但要使组卷的收敛速度得到进一步改进,还需进一步研究。
参考文献
[1] 文海英. 智能型试卷自动生成系统中试卷难度控制技术的研究(j).湖南科技学院学报,2005,26(5):153-156
[2] 常振江. 学生成绩分布与一种简便的评估试卷命题质量的方法(j). 辽宁师范大学学报:自然科学版,2003,26(1):109-112
[3] 丁卫平. 基于遗传算法的智能组卷应用研究.电气电子教学学报(j),2005,27(2):93-95
[4] 朱黎明. 基于单亲遗传算法的试题生成及其应用研究(d). 长沙:湖南大学,2005
[5] t.lynda,c.chrisment,boughanem mohand. multiple query evaluation based on enhanced genetic algorithm. information processing and management,2003,39(2):215-231