摘 要 关联规则挖掘是web使用挖掘的一个重要研究课题,而其中重要的一个问题就是挖掘出的规则的兴趣度评估。在实际的应用中,一般的关联规则算法往往很容易从web数据源中挖掘出大量的规则,而这些规则中,大部分对于用户来说是不感兴趣的。本文结合网络站点拓扑结构,提出了有趣关联规则的算法(mir)。利用页面之间的关联概率对所产生的频繁访问页组的有趣度进行评价,得到有趣度高的频繁访问页组。实验显示,mir算法提高了规则的利用率,有效的改善网站拓扑结构。
关键词 有趣关联规则;页面关联概率;频繁访问页组
1 引言
随着互联网技术的快速发展,如何在/pc/">计算机技术研究的一个热点课题。web挖掘是数据挖掘技术在互联网上的重要应用。它主要包含两大范畴:web内容挖掘和web使用挖掘。
关联规则挖掘是web使用挖掘的一个重要研究课题。它的目的是找到网站资源访问记录中隐含的相互关系,能够发现隐藏的用户访问模式。本文着重讨论了有趣关联规则的挖掘。通过分析日志文件,我们可以寻找到那些经常被用户访问的页面及他们之间的关联规则(即频繁访问页组)。www.11665.Com但是,这些挖掘的结果应该考虑到规则的有趣度。兴趣度低的规则对于网站的结构调整和整体设计无重大意义。在本文中我们认为一个兴趣度高的用户频繁访问页组满足三点:
(1)页组内页面本身之间链接程度低。
(2)页组内尽可能包含多的页面。
(3)经常被用户在一次浏览过程中访问。
2 关联规则
关联规则的问题描述如下:
设r = { i1,i2,⋯,im} 是一组物品集,w 是一组事务集。w 中的每个事务t 是一组物品,t < r。假设有一个物品集a,一个事务t,如果a < t,则称事务t 支持物品集a 。关联规则就是如下形式的一种蕴含:a →b,其中a,b是两组物品,a < i,b < i,且a ∩b 为空。则可用两个参数可信度和支持度来描述关联规则的属性,其定义如下:
(1) 可信度(confidence) 。设w 中支持物品集a 的事务中,有c %的事务同时也支持物品集b,则称c %为关联规则a →b 的可信度。
(2) 支持度( support) 。设w 中有s %的事务同时支持物品集a 和b,则称s %为关联规则a →b 的支持度。显然可信度是对关联规则准确度的衡量,支持度则是对关联规则重要性的衡量。关联规则的挖掘问题就是在事务数据库d 中找出具有用户给定的最小支持度minsup 和最小可信度
minconf的关联规则。他可以分解为两个子问题:
(1) 找出存在于事务数据库中的所有大物品集。物品集x 的支持度support ( x) 不小于用户给定的最小支持度minsup,则称x 为大物品集。
(2) 利用大项集生成关联规则。对于每个大项集a,若b < a,b 不为空,且confidence ( b →( a - b ) ) ≥minconf,则构成关联规则b →( a - b) 。
网站资源可以是网页、数据、图片、声音和文档。设x1、x2、……xm;y1、y2、……ym均为网站资源,x=>y(sup,conf)表示资源集的关联规则,其中x={x1、x2……xm},y={y1、y2、……ym},x∩y=空,这条规则的含义是如果资源集x被访问,那么资源集y也会被访问。规则的支持度为sup,置信度为conf,关联规则挖掘算法的目的就是要推导出所有达到一定支持度和置信度的规则。
但是,只使用支持度和置信度来描述关联规则是明显不足的,规则过多,用户不感兴趣,规则很难为用户服务和利用。这样的关联规则意义就不是很大。所以,结合网站的拓扑结构提出了mir算法来增加挖掘规则的有趣性。
3 有趣关联规则mir算法
3.1 页面之间的关联概率
在这里,假定超文本系统仅仅包含有一些基本的页面。除此外我们还假设:① 指向一个页面的连接是将这个页面作为一个整体来对待的,而不是指向页面内容的一部分;② 在超文本系统中不存在环路;③ 在任何源节点和目标节点间最多只有一条链路。基于以上的假设,我们可以为超文本系统建立一个有向网络拓扑图,如图1 所示:
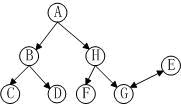
图1 网络拓扑图
在这里,有向图g=(n,e),其中n 是节点的集合,e 是边的集合。一个节点a(a∈n)和一个页面相对应,一条边是一个元组(a,b)∈e,和页面间的一个连接相对应;对于给定的连接(a,b)称a是源节点,b是目的节点。在这里并不假定图是连接的。如果两个页面在网络拓扑中相距较远,则表明它们之间的关联性较低,如果我们从日志信息中挖掘出它们之间有较高的访问可信度的规则,则这样的规则是用户感兴趣的。如图1的页面c和e在拓扑结构中,显示关联度较低。如果,在web日志中发现了c=>e这样的关联规则,则兴趣度是较高的。通过这样兴趣度高的关联规则,有利于网站结构的调整。在介绍算法前,我们首先引入几种资源链接情况的关联概率。
(1)如果在资源a、b之间不存在任何有向边或者链接序列,则p(a|b)=0。
(2)如果资源之间存在有向边链接,假定b中存在li个链接(li>=1),则用户可能从b访问a的概率为p(a|b)=1/(li+1)(包括后退的情况)。如图1中p(c|b)=1/3。
(3)如果a,b之间存在有向序列(a,k1,k2,…b),则p(a|b)=p(k1|b)p(k2|k1)…p(a|kn)。
3.2 规则的有趣度确定
web关联规则挖掘可以利用网络拓扑的特点进行改善。网络拓扑是一个由链接连接起来的资源集。在网络拓扑中直接或间接相连的资源集在用户访问时同时出现的可能性较高,显然他们的关联规则对于网络拓扑设计者是不大感兴趣的。而在拓扑中不相连或相距较远的资源集在用户访问时同时出现的可能性较低,他们的关联规则恰好是网络设计者所期望取得的。在这里,我们定义有趣度公式如下:
interest(a|b)=1-p(a|b) (1)
在拓扑结构中,关联度越高则兴趣度越低。如果页面间没有任何链接,则其interest为1。
当然,我们可以考虑页面内容及访问该页面时间长短和访问频率等多种因素来考虑兴趣度,但是这样实现的时候cpu花费的时间比较多,在这里我们考虑了比较简单实用的方法确定的规则有趣度。
3.3 有趣关联规则算法(mir)
挖掘频繁访问页组的算法类似于关联规则算法中发现最大项目集,我们预先设定支持度的阀值t,在频繁访问页组中都是支持度大于t的页面,在传统的页面聚类算法中,支持度指包含页组中所有页面的用户会话的个数。在mir算法中,我们除了设定支持度,同时根据网站的拓扑结构计算每个规则的有趣度interest(a|b)。挖掘出来的页组的有趣度还需要满足用户指定的最小兴趣度min-interest。
在算法中,我们先用floyd算法求得a到b的最短有向路径,然后利用上面讨论的公式计算p(a|b),进行页面间关联概率的计算。mir算法预先计算任意页面之间的最短路径,存储在邻接矩阵中,提高算法的运行效率。构造最短路径的算法描述如下:
queue=enqueue(index)//从第一个页面开始
p=new node();//新建一个节点
while not empty(queue)
i=dequeue();//从队列中取出一个页面
for each j=i.link //对于该页面的每个链接
if not visited[j] then //判断页面j在图g中是否已有结点
s=s+1;
q=new node();
enqueue(q);
visited[j]=true;
else
q=getnode[j];//获取页j在图g中的结点
endif
p(j|i)=1/(s+1);//根据公式计算关联概率
p.addedge(q,p(j|i));//从p节点增加有向边到q,概率为p(j|i)
next
end
有趣规则算法:
输入:支持度大于最小支持度t的频繁访问页组{a=>b},最小有趣度min-interest;
输出:有趣频繁访问页组;
利用上面的算法构造了一个含有任意页面最短路径的邻接矩阵w
for each a=>b
利用式(1)和w计算interest(b|a);
if interest(b|a)>min-interest then
输出”a=>b”
end
next
4 实验和结论
mir算法已经在学校网站中的一个星期的日志数据中进行了验证,试验环境是在cpu为piv1.3g,内存为256m的pc机上,运行平台为windows2003 server。实验数据长度为6mb的长度,其中包含7万条记录。日志数据中312个不同的页面。经过预处理后转为1703条会话记录。我们用一般的页面聚类算法(支持度大于t)和mir算法都对实验数据进行挖掘,得到的频繁项目集fgi列表如表1所示。
表1 算法实验比较
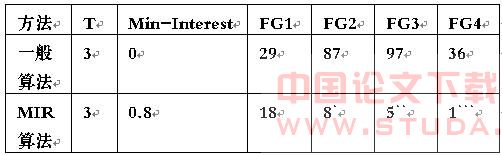
说明:|fgi|-频繁项目集的数目。
+,++,+++:这三个页组包含了我们感兴趣的页组。
通过实验可以发现通过mir算法设定最小兴趣度0.8,对一般算法产生的关联规则进行兴趣度过滤,将兴趣度低的关联规则排除,这样得到规则的兴趣度比较高,在实验中图1的网络拓扑结构产生了如abd=>f和ae=>c这样的有趣频繁访问页组。我们可以根据这样兴趣度高的规则来调整和改善网络的拓扑结构。网络拓扑修改后如图2所示:
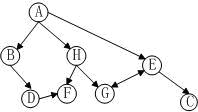
图2 改善的网络拓扑结构
实验结果表明:mir算法在规则的有趣度方面有较大的改善,大大提高规则的利用率,可以很好的用于网络拓扑结构的改善。
参考文献
[ 1 ] r agrawal,t imielinski and a swami. mining association rulesbetween sets of items in large databases[m ]. washington,d. c.sigmodp93,207 - 216
[ 2 ] r agrawal and r srikant. fast algorithms for mining associationrules[ c ]. in j. b. bocca,m. jarke,and c. zaniolo,editors,proceedings 20 th international conference on very large databas2es,morgan kaufmann,1994. 487 - 499
[ 3 ]g liu,h lu,y xu,j x. yu. ascending frequency orderedprefix - tree:efficientmining of frequent patterns [ c ]. proc.2003 int. conf. on database systems for advanced app lications(dasfaap03),kyoto,japan,march 2003
[ 4 ]mohammad el - hajj and osmar r za? ane,cofi - treemining[ c ]. a new app roach to pattern growth with reduced candida2cy generation,in workshop on frequent itemsetmining imp le2mentations ( fim ip03) in conjunction with ieee - icdm 2003,melbourne,florida,usa,19 november,2003
[ 5 ]han j,pei j,yin y. m ining frequent pat ternsw ithoutcandidate generat ion [a ]. p roc 2000 a cm 2s igm odint conf on m anag em ent of d ata (s igm od ′00) [c ].dallas,2000. 1212
[6 ]周欣,沙朝锋,朱杨勇,施伯乐.兴趣度――关联规则的又一个阀值.计算机研究和发展,2000.5