[摘要] 构造一个新的hash函数,结合索引顺序表和二分检索法的思想,提出了一种高效率的信息检索算法,通过理论计算和实验证明此算法的平均检索长度小于1.352(n>100)。
[关键词] hash函数检索平均检索长度
信息时代如何提高信息检索的效率一直是信息管理人员关注的问题。提高信息检索效率的有效途径是构建被检索信息与其存放地址之间的关系(hash)。到目前为止,构造hash函数的方法很多,常用的方法有:直接定址法、数字分析法、平方取中法、折叠法、除留余数法、随机数法等转换算法。但是不论哪种算法都会出现“碰撞” 现象 , 因而就限制了上述方法的普遍使用。为了解决或减少“碰撞”,我们把hash的思想和索引顺序表检索的思想,以及二分检索法的思想结合起来提出一种基于hash表的二分检索法,通过理论分析和实验证明,该算法检索效率极高。
一、hash函数的构造
桶排序法,先把被排数据所分布的区间[dmin,dmax](在这里dmax,dmin分别为被排数据的最大,最小值)划分成n个大小相等的子区间,称子为“桶”,然后将n个数据根据其大小分配入相应的“桶”内(桶[1],桶[2],…,桶[n])。借签桶排序中将数据根据其大小分配入相应“桶”的思想,我们在检索时将已排好序的数据也根据其大小将其分配入相应的“桶”内,然后再在“桶”内进行二分检索。假设按升序排列的n个数据已存放在data数组的元素 data[0]~data[n-1]中,构造一个hash 函数为:
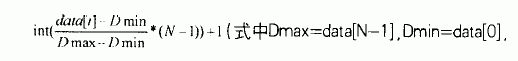
(式中dmax=data[n-1],dmin=data[0],n为数据个数)
二、基于hash函数的二分检索算法hs
算法hs使用二个数组,data数组的元素 data[0]~data[n-1]中存放按升序排列的n个数据,address数组的元素address[1]~address[n]中用来存贮经hash函数转换后得到相同地址的数据个数。WWW.11665.Com
算法hs
hs1[清address数组]将ddress[1]~address[n]都置0
hs2[dmax中置最大值、dmin中置最小值]dmax←data[n-1],dmin←data[0]
hs3[i置初始值] i←0
hs4[求数据data[i]的hash变换后的地址ad]ad

hs5[地址“碰撞”记数器address[ad]加1] address[ad] ←address[ad]+1
hs6[修改i] i←i+1
hs7[比较i与n-1] 若i<=n-1,则转hs4,否则转hs8。
hs8[address[0]置初值1]address[0] ←1
hs9[j置初始值]j←1
hs10 [求地址发生“碰撞”的数据在data数组中的首地址]address[j]=address[j]+address[j-1]
hs11[修改j] j ←j+1
hs12 [比较j与n] 若j<=n 则转hs10,否则转hs13。
hs13 [输入一个被检索的数据 x]
hs14[对被检索数据x 用hash 函数得地址ad]
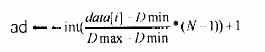
hs15 [确定“块”的下界low,上界high的值] low←address[ad-1],high←address[ad]-1
hs16 [在“块”内进行二分检索] 在给定的下界与上界之间进行二分检索,若找到,则返“检索成功”信息,否则返加回“检索失败”信息。
hs17 [本算法结束]
三、平均检索长度的分析
在本检索算法中,首先将被检索数据x经hash函数转换出一个地址,根据这个地址将被检索的数据直接定位到相应的“块”中,然后在“块”中进行二分检索。 因此通过对所有“块”内二分检索法的平均检索长度的计算就可求出本算法的平均检索长度。二分检索法的平均检索长度为:
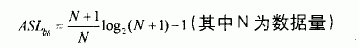
下面我们来求本算法的平均检索长度。假设在n个数据均匀分布的情况下,经过本检索算法中hash函数转换,每一个地址出现的概率相同,都等于1/n,因此,有m个数据转换得到相同地址的概率为:
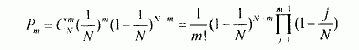
(m=1,2,…,n)
参考文献[1] 的附录中已证明:
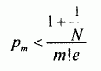
(1)
所以本检索算法的平均检索长度为
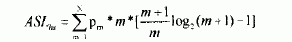
(2)
由上式(1)和式(2)两个公式即可求得本算法的平均检索长度,其平均检索长度小于1.352(当n>100时)。
四、算法分析与实验结果
1.本算法的创新之处在于通过hash函数可将被检索的数据x直接位置定位到相应的“块”(通过hash函数转换后的地址相同的数据区间)中,再在“块”中进行二分检索。从而不再需要建立索引顺索表检索算法中的索引表,也就省去了索引顺索表检索算法中查找索引表确定所在“块”的平均检索长度。
2.此方法突破了 hash 表的平均检索长度是装填因子(=( 表中填人的记录数 )/( 哈希表的长度 ) 的函数 , 而不是 n 的函数的弱点。
3.在理想情况下,即数据完全是均匀分布的情况下 ,本算法的平均检索长度可达理论极限值 asl=1。即使是在最坏的情况下, 当 n 个数据经hash 函数转换后的地址均相同,所有数据均落在同一个“块”中, 其平均检索长度 asl 也只会下降到二分检索法时的平均检索长度。
4.本算法对于均匀分布的数据是极为有效的, 通过计算得出其平均检索长度小于1.352(n>100时),因此检索效率很高。
5.本算法中的步骤hs1~hs12仅仅是为检索作的准备工作,相当于初始化的工作,只需在检索开始时做一次即可。
6.实验结果。为了对本检索算法的检索效率进行验证,我们用vb6.0编写了本算法以及二分检索法的程序,将二种检索算法的平均检索长度进行实际测定,实验中所用的数据由vb6.0的随时函数产生,数据的范围为(0~10000),实验结果如下表所示:
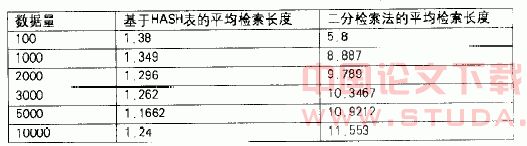
vb6.0程序二种检索算法平均检索长度对比表
我们在实验中测定平均检索长度时,通过程序对所有数据逐个检索,统计出检索完所有数据需进行比较的总次数再除以数据总数后得出。上表中当n=100时,本算法实际测定的值(1.38)与理论计算(1.352)略有误差,原因是我们用vb6.0中的随机函数产生的随机数在数据量较小时分布不一定很均匀。从表1中可以看到:当数据量稍大一些(n>100),本算法的平均检索长度的实测结果完全与理论分析一对致,并且远小于二分检索法的平均检索长度。本算法的平均检索长度随着数据量n的增加几乎不变。