摘 要: 为了更加准确地预测城市地铁交通中动态变化的客流量,通过分析城市地铁交通客流量的特点,提出了一种基于神经网络数据融合的预测方法。这种方法根据预测数据各属性的特点,将采集的数据提取出多个相关序列。在此基础上对各序列采取不同的处理、预测方法,再利用神经网络进行融合。这种方法可用于数据动态预测的各种领域。实验表明,采用这种方法可以有效地改善数据预测的误差。
关键词: 铁路交通; 信息预测; 数据融合; 神经网络
在城市地铁交通中,各车站交通流量信息(如候乘数量、下车数量等) 的准确预测有利于地铁运行高效、及时地调度,从而既达到增加效益的经济目的,又可以更好地满足人们的乘车需求。传统的预测方法有回归分析算法以及kalman 滤波等。这些方法假定过程是平稳的,系统是线性的,系统的干扰是白噪声,因此在线性系统平稳的随机时间序列预测中能够获得满意的结果。然而,交通问题是有人参与的主动系统,具有非线性和扰动性强的特征,前述方法难以奏效,表现为以下缺点: ① 每次采样的数据变化较小时适用,数据变化大误差就大; ② 预测值的变化总是滞后于实测值的变化; ③ 无法消除奇异信息的影响。基于小波分析的动态数据预测方法以小波变换后的数据进行预测,克服了传统预测方法不能消除奇异信息的缺点, 有效地预测动态的流量信息[ 1 ] 。但该方法只能对单个的数据序列进行处理,而事实上能够用于预测的数据可以是多方面的。
数据融合(data2fusion) 技术起源并发展于军事领域,主要用于目标的航迹跟踪、定位与身份识别以及态势评估等[ 2 ] 。WWW.11665.cOM传统的数据融合技术大多采用概率理论(如bayes 决策理论) 对多种信息的获取与处理进行研究,从而去掉信息的无用成分,保留有用成分[ 3 ] 。在信息处理中,分别运用各种体现数据不同属性特征的方法处理(如预测) 后进行融合是一个有待深入研究的问题。为了充分利用各方面已有的数据,获得可靠的交通流量动态预测,本文借鉴数据融合的基本思想,提出了在数据处理方法上的融合预测方法。
1 流量融合预测模型
1. 1 预测模型的结构
由于预测对象的复杂性,为了表现与预测对象相关联的其他对象或属性,每个关联对象(属性) 用一个时间序列来表示,作为预测对象的相关序列。所有用于预测的相关序列构成预测对象的相关序列集。由于在预测中具有不同的作用,各相关序列将使用不同的处理和预测方法。在相关序列集上的地铁客流量融合预测模型结构,如图1 所示。
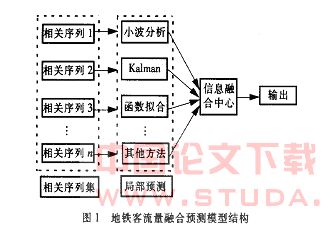
下面针对城市地铁车站客流量的预测进行论述。
1. 2 构造相关序列集
为了预测车站(序号为0)在第i 天t 时刻的流量^f0 i(t) ( 实测值为f0 i(t)) ,设t 时刻^f0 i(t)的相关时间序列集为f(t) = {fj(t) ,1 ≤ j ≤ n} ( 1 ) 式中,fj(t)为t时刻^f0 i(t)的相关时间序列; n 为相关时间序列数。
为了获得精确的预测,可以根据关联特性构造任意多个相关时间序列。本文意在阐明本算法的基本思想,将流量数据仅仅构造为3 类相关序列:当前序列、历史序列和邻站序列。
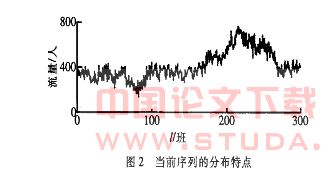
当前序列 预测时刻t之前本站最近k次流量按时间先后记录下来的数据构成的时间序列为当前序列,即
f1 (t) = { f0 i(t -l),1 ≤ l ≤ k} ( 2 )
该序列数据的主要影响因素是时刻,同时还受人为、气温、天气等其他扰动因素的影响,数据分布的非线性特性较大,频带较宽。第l 班列车的流量如图2 所示。
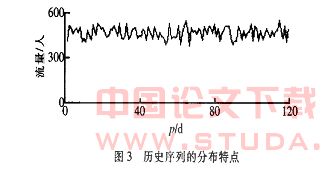
历史序列 同为工作日或同为节假日的相邻数天,其流量曲线形状相对类似,流量曲线相似的日期在预测中具有较大的参考意义。本站最近m 天在时刻t 的流量按日期先后记录下来的数据构成的时间序列为历史序列,即f2 (t) = { f0 i-p(t) ,1 ≤ p ≤ m} ( 3 ) 工作日和节假日流量差别较大,可将它们分类处理。该序列整体分布较平稳,有震荡,但频带较窄。第p个工作日在时刻t的流量如图3 所示。
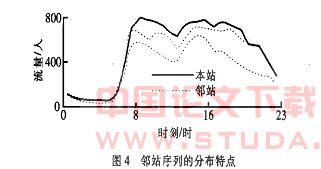
邻站序列 图4 为本站与邻近2 个车站24 h 的流量曲线经db2 小波3 层变换后的近似分量,可见各分量关联性较大。如果根据以前的数据将各邻近车站相互关系解算出来,就可以利用这种函数关系预测时刻t在本站的流量。最近m天在时刻t 的流量按日期先后记录下来的各邻站历史序列为本站的邻站序列,即
qf2 +q(t) = { fi-p(t) ,1 ≤ p ≤ m,1 ≤ q ≤ s} ( 4 )
q式中, fi-p(t)表示第q个邻近站的第(i -p)天的流量;s 表示邻近站数。
1.3 相关序列的预测
由于各相关序列在预测中具有不同的影响,且分布规律和特点差异较大,因而各序列使用不同的预测方法。本文对当前序列进行小波分解后用kalman 预测,对历史序列直接进行kalman 预测,对邻站序列用幂级数多项式进行拟合。
1.3.1 小波分析
根据设置的分解指数η对序列进行小波n 尺度分解,得到一组低频信号和n 组高频信号,对这n + 1 组信号分别用mallat 塔式算法重构到原尺度上,得到n + 1 组在原始尺度上的经过分解重构处理的信号。分别对信号用kalman 滤波进行预测,得到n + 1 个预测值,再将这n + 1 个预测值用权系数合成最终的预测值。具体算法请参见文献[1 ]。
1.3.2 kalman 滤波离散线性kalman 滤波方程为
f(t) = φ(t -1) f(t -1) + w(t -1)( 5 ) 式中,φ (t) 为系统状态转移量; w(t) 为系统误差。kalman 滤波通过t -1 时刻的状态f(t -1)估计t 时刻的状态f(t) 。具体算法请参见文献[1 ]。
1.3.3 多项式拟合
分别对各邻站序列用幂级数多项式拟合本站数据,拟合模型如下
n
i
p
^fp(t) = αp,i(t) f(t) ( 6 )
i=0
i
6 式中, fp (t)为对第p个邻站在时刻t 的流量的i 次i 幂;αp,i(t)为fp (t)的系数。当n= 2 时,上述拟合算法简化为线性回归模型。
1.4 流量的融合预测设预测对象共有n个相关的时间序列fi(t) ,经过预处理分别为fi(t) ,融合预测模型可表示^f(t)在f(t)上的映射,即^f(t) =ζ(f(t)) =ζ(f1 (t) ,f2 (t) ,fn(t)) ( 7 ) 式中,ζ(・)表示映射关系。特别地,式(7)可简化为如下的线性映射组合^f(t) = αi(t)ξ(fi(t)) ( 8 ) i=16
式中,αi(t)为t 时刻的序列fi (t)的权系数;ξ(fi (t)) 为以fi (t)为依据的局部预测值。为了确定上述算法中映射关系ζ(・),本文采用神经网络进行解算。
2 模型的神经网络解算
神经网络是由大量简单的神经元以某种拓扑结构广泛地相互连接而成的非线性动力学系统[4 ]。神经网络在数据融合技术中具有无法替代的作用,通过神经网络对各相关序列的局部预测进行最终融合,具体过程如下。
2.1 数据的局部处理
广州市地铁某站一个方向的流量数据是以每班列车到站上车的人数记录的(流量单位:人/班) 。根据2002 年5 月1 日 2003 年3 月2 日的流量数据,运用本文算法进行预测。按照1.2 节的方法构造了4 个相关序列:当前序列f1 (t) 、历史序列f2 (t)以及相邻2 个车站的邻站序列f3 (t)和f4 (t) 。
2.2 神经网络的设计
因为3 层神经网络可以一致逼近任何非线性函数[5 ]。采用具有单隐层的3 层神经网络作为模型,即输入层、隐层和输出层。
以各相关序列的局部预测值作为输入向量,实测值f(t)为期望输出,有4 个输入节点,1 个输出节点。隐层神经元数量关系到网络的训练速度和精度问题。对于一定数量的样本,需要一定数量的隐层神经元数, 神经元少了,不能反映样本的规律;多了,则神经网络以过于复杂的非线性关系来拟合输入输出之间的关系,使得模型的学习时间大大增加。本例中,8 个隐层神经元数是最好的。以误差平方和sse(sum2squared error ) 作为训练评价标准, sse = p j (ypj-opj)2 ,其中ypj和opj分别为输出层第j个神经元的第p个样本的期望输出和实际输出(本例中j= 1 ,p= 60) 。
用matlab 的ann 工具箱构造神经网络。隐层神经元的激励函数为tansig 函数( 正切s 型传递函数),输出层神经元的激励函数为purelin 函数(线性传递函数),这样整个网络的输出可以取任意值。采取批处理学习方式和快速bp 算法训练。
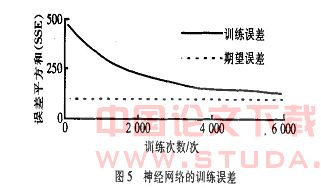
2. 3 神经网络的训练
将网络的训练标准sse 设为64(60 组训练样本), 利用上述样本对神经网络进行训练,训练6 000 次时网络的权值和阈值将达到最佳值,即达到了训练目标。神经网络训练目标接近过程,如图5 所示。
从图5 中可以看出,训练开始时,网络收敛速度较快,接近目标时收敛速度会减慢。可见,训练次数越多,得到的结果越好。当然,这是以训练时间的增长作为代价的。
3 实验对比分析
采用本文算法和传统的kalman 算法分别对2003 年3 月2 日的各整点时刻的流量进行预测。算法各时刻均通过训练后的神经网络预测,预测与实测结果的比较,如图6 所示。
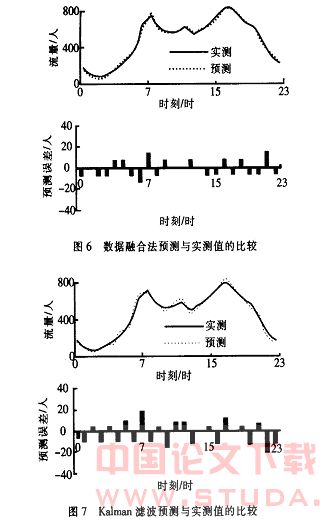
传统的kalman 滤波是直接在当前序列的基础上进行预测的, 预测与实测结果的比较如图7 所示。2 种预测方法的误差指标对比见表1 。
表1 实验结果对比
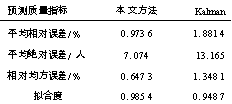
比较可得,由于传统的kalman 预测方法只能以某一类序列的数据作为预测基础,无法利用其他序列信息,且对变化大的数据采样要求较高,因而具有较大的误差,而本文所述方法有效地克服了这些缺点。
4 结论
通过分析城市地铁站客流量的相互关系和特点, 在对流量信息进行以预测为目的相关序列集构造的基础上,提出了一种基于数据融合的预测模型。该预测模型不仅是一个多信息接收和处理的融合模型,而且还是一个动力学系统,网络的训练样本也是动态的,如果训练的次数适当,预测的精度也可以随之变化调整。实验结果表明,基于数据融合的预测与传统的预测方法相比,由于充分利用了所有预测信息,在预测的准确程度上有较大提高。
参考文献:
[1 ] 李存军, 等. 基于小波分析的交通流量预测方法[j ] . 计算机应用, 2003 , 23(12) : 7 ―8.
[2 ] 权太范. 信息融合: 神经网络 模糊推理理论与应用[m] . 北京: 国防工业出版社, 2002.
[3 ] 李洪志. 信息融合技术[ m ] . 北京: 国防工业出版社, 1996.
[4 ] 靳蕃. 神经计算智能基础 原理方法[ m] . 成都: 西南交通大学出版社, 2000.
[ 5 ] rumelhart d e . learning representation by back2 propagating errors [j ] .nature , 1985 , 51(4) :533 ―536.