摘 要 本文通过对基本遗传算法添加初始化启发信息、改进交叉算子和利用本身所固有的并行性构架粗粒度并行遗传算法等方法提高了遗传算法的收敛性及其寻优能力。
关键词 遗传算法;tsp;交叉算子
1 引言
遗传算法是模拟生物在自然环境中的遗传和进化过程而形成的一种自适应全局优化概率搜索算法。总的说来,遗传算法是按不依赖于问题本身的方式去求解问题。它的目标是搜索这个多维、高度非线性空间以找到具有最优适应值(即最小费用的)的点
[1]。
基本遗传算法是一个迭代过程,它模仿生物在自然环境中的遗传和进化机理,反复将选择算子、交叉算子和变异算子作用于种群,最终可得到问题的最优解和近似最优解。
2 遗传算法程序设计改进比较
2.1 基本遗传算法对tsp问题解的影响
本文研究的遗传算法及改进算法的实现是以c
++语言为基础,在windows2000的版本上运行,其实现程序是在microsoft visual stadio 6.0上编写及运行调试的。wWw.11665.cOM
1) 遗传算法的执行代码
m_tsp.initpop(); //种群的初始化
for(int i=0;i<m_tsp.returnpop();i++)
m_tsp.calculatefitness(i); //计算各个个体的适应值
m_tsp.statistics(); //统计最优个体
while(entropy>decen||variance>decvar)//m_tsp.m_gen<100)
{
//将新种群更迭为旧种群,并进行遗传操作
m_tsp.alternate(); //将新种群付给旧种群
m_tsp.generation(); //对旧种群进行遗传操作,产生新种群
m_tsp.m_gen++;
m_tsp.statistics(); //对新产生的种群进行统计
}
2) 简单的遗传算法与分支定界法对tsp问题求解结果的对比
遗传算法在解决npc问题的领域内具有寻找最优解的能力。但随着城市个数的增加,已没有精确解,无法确定遗传算法求解的精度有多高。一般情况下,当迭代代数增大时,解的精度可能高,但是时间开销也会增大。因此可以通过改进遗传算法来提高搜索能力,提高解的精度。
表1 10个城市的tsp问题求解结果数据
算法
试验结果
简单遗传算法
分支定界法
最佳解
时间
精确解
时间
试验1
2448.610037
5s
2448.610037
00:07:30
试验2
2448.610037
13s
试验3
2448.610037
9s
试验4
2459.543054
10s
试验5
2459.543054
7s
2.2 初始化时的启发信息对tsp问题解的影响
1) 初始化启发信息
在上述实验算法的基础上,对每一个初始化的个体的每五个相邻城市用分支界定法寻找最优子路径,然后执行遗传算法。
2) 遗传算法与含有启发信息的遗传算法求解结果的对比
当城市数增至20个时,用分支定界法已经不可能在可以接受的时间内得到精确的解了,只能通过近似算法获得其可接受的解。试验设计中算法的截止条件:固定迭代1000代。表2中的平均最优解为经过多次试验(10次以上)得到的最优解的平均值,最优解的出现时间为最优解出现的平均时间,交叉操作次数为最优解出现时交叉次数的平均值。
表2 20个城市的tsp问题求解结果数据
算法
交叉操作
次数
最优解
出现时间
平均
最优解
简单遗传算法
80244.4
79.4s
1641.8
含初始化启发信息的ga
79000.2
37.4s
1398.9
从表2中可以看出,当初始种群时引入启发信息将提高遗传算法的寻优能力。同时缩短了遗传算法的寻优时间和问题的求解精度。
2.3 交叉算子对tsp问题解的影响
1)循环贪心交叉算子的核心代码
for(i=1;i<m_chrom;i++)
{
flag=0;
city=m_newpop[first].chrom[i-1]; //确定当前城市
j=0;
while(flag==0&&j<4)
{
sign=adjcity[city][j]; //adjcity数组的数据为当前城市按顺序排列的邻接城市
flag=judge(first,i,sign); //判断此邻接城市是否已经存在待形成的个体中
j++;
}
if(flag= =0) //如果所有邻接城市皆在待扩展的个体中
{
while(flag= =0)
{
sign=(int)rand()/(rand_max/(m_ chrom-1)); //随机选择一城市
flag=judge(first,i,sign);
}
}
if(flag==1)
m_newpop[first].chrom[i]=sign;
}
2)问题描述与结果比较
下面笔者用经典的测试遗传算法效率的oliver tsp问题来测试循环贪心交叉算子的解的精度和解效率。oliver tsp问题的30个城市位置坐标如表3所示
[2]。
表3 oliver tsp问题的30个城市位置坐标
城市编号
坐标
城市编号
坐标
城市编号
坐标
1
(87,7)
11
(58,69)
21
(4,50)
2
(91,83)
12
(54,62)
22
(13,40)
3
(83,46)
13
(51,67)
23
(18,40)
4
(71,44)
14
(37,84)
24
(24,42)
5
(64,60)
15
(41,94)
25
(25,38)
6
(68,58)
16
(2,99)
26
(41,26)
7
(83,69)
17
(7,64)
27
(45,21)
8
(87,76)
18
(22,60)
28
(44,35)
9
(74,78)
19
(25,62)
29
(58,35)
10
(71,71)
20
(18,54)
30
(62,32)
表4 贪心交叉与部分匹配交叉的比较(oliver tsp问题的30个城市)
交叉算子
交叉操作次数
平均时间
平均最优解
部分匹配交叉
59760
31.2s
517.0
贪心交叉
15774
28.6s
433.4
从表4、图1中可以看到,贪心交叉算子大大提高了遗传算法的寻优能力,同时也降低了交叉操作次数。在多次试验中,贪心交叉算子找到的最优解与目前记载的最佳数据的误差率为2.7%。而部分匹配交叉算子找到的最优解与目前记载的最佳数据的误差率高达7%。从而可以得到交叉算子对于遗传算法
的计算效率和计算结果起主导性作用
[3]。
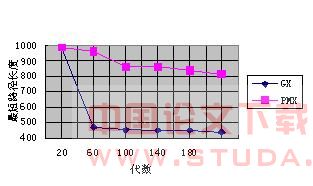
图1 遗传算法的收敛过程
2.4 并行遗传算法消息传递实现的核心代码
1)主程序代码
//接收各个从程序的最优个体
for(i=0;i<slave;i++)
{
mpi_recv(rchrom[i],chrom,mpi_unsigned,mpi_any_source,gen,mpi_comm_world,&status);
}
//计算接收各个从程序的最优个体的回路距离
for(i=0;i<slave;i++)
{
fitness[i]=0.0;
for(int j=0;j<chrom-1;j++)
fitness[i]=fitness[i]+distance[rchrom[i][j]][rchrom [i][j+1]];
fitness[i]=fitness[i]+distance[rchrom[i][0]][rchrom [i][chrom-1]];
}
//找到最优的个体并把它记录到文件里
for(i=0;i<slave;i++)
{
if(1/fitness[i]>min)
{
sign=i;
min=1/fitness[i];
}
}
fwrite(&gen,sizeof(int),1,out);
for(i=0;i<chrom;i++)
fwrite(&rchrom[sign][i],sizeof(unsigned),1,out);
fwrite(&fitness[sign],sizeof(double),1,out);
//每九代向从程序发送一个最优个体
if(gen%9==0)
mpi_bcast(rchrom[sign],chrom,mpi_ unsigned,0,mpi_comm_world);
2)从程序代码
//将上一代的最优个体传回主程序
mpi_send(rchrom1,chrom,mpi_unsigned,0,gen,mpi_comm_world);
//每九代接收一个最优个体并将其加入种群中替换掉最差个体
if(gen%9==0)
{
pi_bcast(rchrom2,chrom,mpi_unsigned,0,mpi_comm_world);
tsp.indialternate(rchrom2);
}
//进行下一代的计算
tsp.aternate();
tsp.generation();
tsp.statistics();
3)并行遗传算法的性能
笔者在mpi并行环境下,用c
++语言实现了一个解决tsp问题的粗粒度模型的并行遗传算法。该程序采用的是主从式的mpi程序设计,通过从硬盘的文件中读取数据来设置染色体长度、种群的规模、交叉概率和变异概率等参数。试验环境为曙光tc1700机,测试的对象是oliver tsp问题的30个城市的tsp问题。
正如在测试串行遗传算法所提到的数据结果,并行遗传算法也没有达到目前所记录的最好解,但是它提高了算法的收敛性,并行遗传算法的收敛趋势如图2所示
[4]。
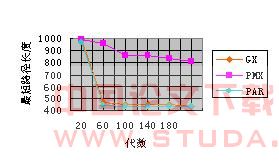
图2 遗传算法的收敛过程
3 结束语
本文通过对基本遗传算法的不断改进,证明了添加启发信息、改进遗传算子和利用遗传算法固有的并行性都可以提高遗传算法的收敛性,其中对遗传算法交叉算子的改进可以大大提高遗传算法的寻优能力。
参考文献
[1] 刘勇、康立山,陈毓屏著. 非数值并行算法-遗传算法.北京:科学出版社 1995.1
[2] i m oliver d j smith and j r c holland,a study of permutation crossover operators on the traveling salesman[c]// problem of the second international conference on genetic algorithms and their application,erlbaum 1897: 224-230
[3] 于海斌,王浩波,徐心和. 两代竞争遗传算法及其应用研究 .信息与控制,2000 vol.29,no.4:309-314
[4]穆艳玲,李学武,高润泉. 遗传算法解tsp问题的并行实现.北京联合大学学报(自然科学版),2006 vol.20 no.2: 40-43