摘 要 描述了web日志数据预处理技术的一种改进技术――frame过滤技术,对其关键部分与运作模式进行了研究与改进。讨论了frame页面过滤预处理技术在web页面挖掘中的效率问题,分析了决策树算法中最著名的算法――id3算法,并用id3算法对frame过滤算法进行了改进,比较新旧算法的执行效率及算法结果质量,得出了新算法执行效率更高及质量更好的结论,从而搞高了对存在frame页面的网站实施web日志挖掘算法时挖掘结果的兴趣度。
关键词 id3算法;web日志挖掘;web日志预处理;frame页面过滤
1 引言
internet的迅速发展使得web为人们提供了内容丰富且数量庞大的信息,随着数据挖掘技术的出现以及发展,数据挖掘逐渐被应用于web数据。
web日志挖掘是三大类web挖掘之一,它主要包括数据预处理和挖掘算法实施两个主要阶段.实施挖掘算法之前要对web日志文件进行预处理,将其转化为用户会话集.本文着重讨论web日志挖掘预处理技术中的frame页面过滤预处理技术,即在传统的web日志预处理过程中加入frame页面过滤这一步骤,并提出了用决策树算法著名的id3算法进行frame页面过滤,进一步提高了日志数据预处理的质量和效率,从而为挖掘算法的实施提供更为准确的数据,提高了对存在frame页面的网站实施web日志挖掘算法时整个web日志挖掘的效率及挖掘结果的兴趣性。Www.11665.com
2 web日志预处理中的frame页面过滤技术[2]
2.1 web日志预处理技术现状
web日志挖掘[1] [3-4]是指将数据挖掘技术应用于web服务器日志文件,以发现隐藏在其中的用户访问模式。web日志预处理是在web日志挖掘前,对web日志进行清理、过滤以及重新组合的过程,其目的是剔除日志中对挖掘过程无用的属性及数据,并将web日志数据转换为挖掘算法可识别的保存形式。
到目前为止提出的web日志的预处理技术,它包含三种方法识别用户的活动集合:
(1) web服务器提供cookie,则具有相同cookie值的页面请求是来自同一个用户,则用户会话识别的主要的任务就是将web日志划分为不同cookie值所对应的页面请求集合。
(2) web服务器没有提供cookie,但每个网站用户都要一个登录标识符方可访问站点,则分析工具即可利用登录标识符识别会话。
⑴ 如果web服务器既没有cookie也没有登录标识符,可以利用主机地址,同时分析日志中每条记录的请求页和引用页的url,然后根据web站点的拓扑结构(超链接)和其它启发式规则识别用户会话,但是这种方法的精确度较低,不能100%正确地识别出每个请求对应的用户。
这里主要讨论第3种预处理方法。
一般web日志预处理主要包括:数据净化、用户识别、会话识别、路径补充、事务识别
数据净化指删除web服务器日志中与挖掘算法无关的数据。由于在web日志中通常只有html文件与用户会话相关,所以通过检查url的后缀删除不相关的数据。
用户识别是指要识别出每个访问网站的用户。一般web日志挖掘工具中常使用基于日志/站点的方法,并辅助一些启发式规则帮助识别用户。
会话识别是将用户的访问记录分为单个的会话。通常采用超时方法识别用户会话,如果两页间请求时间的差值超过一定的界限(超时阈值)就认为用户开始了一个新的会话。
路径补充是由于本地缓存和代理服务器缓存的存在,使得服务器的日志会遗漏一些重要的页面请求。路径补充就是将这些遗漏的请求补充到用户会话中,解决的方法类似于用户识别中的方法。
事务识别,用户会话是web日志挖掘中唯一具备自然事务特征的元素,但是,对于某些挖掘算法来说可能用户会话的粒度太大,需要利用分割算法将其转化为更小的事务。
一般通常采用图1所示的数据预处理过程。
如果按照前面所介绍的日志预处理技术对web日志进行预处理,则frame页面和其subframe页面也将一起出现在用户会话文件中。在这样的用户会话文件上进行数据挖掘,frame页面和subframe页面作为频繁遍历路径或者频繁访问页组出现的概率很高,并且他们同时出现在挖掘结果中,这就降低了挖掘结果的兴趣性。
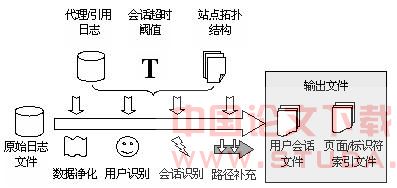
图1 典型的web日志数据预处理过程
2.2 frame页面过滤预处理技术
html规范通过“frame”标记支持多窗口页面,每个窗口里装载的页面对应一个url。 当用户请求frame页面的url时,frame页面和其中的subframe页面作为一个多窗口页面展现在用户面前,我们可以将用户对frame页面的请求看成就是对多窗口页面的请求。这样,在数据预处理阶段将frame页面和其中的subframe页面作为一个整体考虑,并且把frame页面对应的url当作这个整体的代表。从全局而言,这样处理可以有效地消除frame页面对日志挖掘的影响,最终提高挖掘结果的兴趣性。
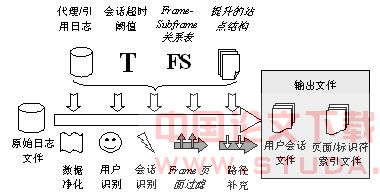
图2 改进的web日志数据预处理过程
为此,我们对图1中描述的常用的web日志数据预处理技术进行相应的改进,图2是改进后的数据预处理过程。
改进的web日志数据预处理过程中,在会话识别与路径补充这两个步骤之间增加了frame页面过滤。frame页面过滤要完成的任务是,根据从站点的拓扑结构中提取出的frame-subframe关系表,从会话识别过程中生成的会话文件中,寻找frame页面及其subframe页面,将会话文件中对frame和其subframe页面的请求用frame页面代替,从而删除会话文件中多余的subframe页面。由于删除了会话文件中的subframe页面,因此会丢失subframe页面中包含的超链接信息,所以接下来的路径补充步骤中必须使用提升的站点结构。
3 基于id3算法的frame页面过滤预处理技术
如上文所述,我们应用frame页面过滤技术有效地消除了frame页面对日志挖掘的影响,然而我们知道web日志挖掘的记录是成千上万的,上述frame页面过滤算法中是对每个用户对话的每个页面进行是否frame和subframe的判断,并且对判断出的子框架逐个地进行删除,而且因为subframe页面的删除导致后面必须用提升的站点结构,虽然较一般预处理技术增加了兴趣度,但是效率还是比较低的,而且也增加了开销。并且subframe过滤中被删去,在后面的路径补全中能否完全恢复也值得高榷。而且有快速分类性质允许多粒度层的决策树分类算法可以解决此问题。本文在此用决策树算法[1] [3]中著名的id3算法对提高frame过滤效率进行了一些探讨
3.1 id3算法[1] [3]的描述
id3算法的基本思想是贪心算法,采用自上而下的分而治之的方法构造决策树。首先检测训练数据集的所有特征,选择信息增益最大的特征a建立决策树根节点,由该特征的不同取值建立分枝,对各分枝的实例子集递归,用该方法建立树的节点和分枝,直到某一子集中的数据都属于同一类别,或者没有特征可以在用于对数据进行分割。
算法描述如下:
算法:generate-decision_tree 由给定的训练数据集产生一棵决策树。
输入:训练样本samples,由离散值属性表示;候选属性的集合attribute_list
输出:一棵决策树
方法:
1) 创建结点n
2) if samples 都在同一类c then
3) 返回n 作为叶结点,以类c标记;
4) if attribute_list为空 then
5) 返回n作为叶结点,标记为samples最普通的类;//使用多数表决。
6) 选择 attribute_list中具有最高信息增益(关于信息增益的求法请参见文献[3])的属性test_attribute;
7) 标记结点n 为test_attribute;
8) for each test_attribute 中已知值a
i //划分sample;
9) 由结点n长出一个条件为test_attribute=a
i的分枝;
10) 设s
i是sample 中test_attribute=a
i 的样本集合//一个划分
11) if s
i 为空 then
12) 加上一个树叶,标记为samples中最普通的类;
13) else 加上一个由generate_decision_tree(s
i,, attribute _list_返回的结点
3.2 基于id3算法的frame页面过滤算法与效率分析
输入:
fs表(
pidframe ,
pidsubframe)对的集合;侯选属性的集合attribute_list(包括index.html,top.html,left.html,main.html……)
输出:一棵判定树
for each user session <userid,[pid1,pid2,pidk> {
currentframe=null
make_node(web)
if((currentframe,
pidi) ∈fs
)
make_tree(currentframe,web_left)
else if(
pidi∈dom(fs))
{currentframe=
pidi
make_decition_tree(currentframe,web_right)
}else make_decisiton_tree(current,web_left)
if attribute_list=null {
make_decition_tree(currentframe,web_right);}
else if gain(one of attribute_list)>allgain (attribute_ list); //gain()为信息增益函数
currentframe=test_attribute;
for
ai of each test_attribute
if not(test_attribute=
ai)
make_desition_tree(
ai,web_left)
else generate_decision_tree(
ai,web_right)
}
我们在这里认为网页上每个页面都是web页面,所以它的信息增益最高,因此以它为根结点。
currentframe变量记录了当前处理的页面,如果当前页不是frame页面时则将其添到左子树中,否则,即
pidiî
dom(
fs),则将当前页面的标识符
pidi赋给
currentframe,并将其添加到右子树中,且将它包含的subframe页面仍添加到左子树中。因为我们感趣的页面是frame页面,所以它的点击率最高,其信息增益最大,因此我们将信息增益最大的总是添加到web右子树中,而当前页不符合frame页面属性的就是subframe页,将其添加到左子树中。这样,决策树的右枝就是frame,左枝就是subframe.很容易就完成了会话识别,并且因为subframe并没有被删去,因此在后面的路径补充中将其复原就可以了。较之frame过滤算法,此算法略去了提升站点结构这一步,因此更大地提高了提高了日志数据预处理的速度及预处理结果的质量。
3.3 数据分析
用长度为9mb的日志,其中包含10万条记录。日志数据中有417个不同的html页面,从中识别出1902个用户会话。通过挖掘频繁访问页组比较一般数据预处理技术frame页面过滤预处理技术和基于id3页面过滤预处理技术。其算法比较如下表
方法
绝对
支持度
|fg
1|
|fg
2|
|fg
3|
|fg
4|
|fg
5|
|fg
6|
|fg
7|
一般技术
70
23
57
80
60
24
3*
0
60
24
77
94
65
25
4*
0
frame
改进技术
30
23
31
16
2
+
0
0
0
15
55
100
72
20
3
++
0
0
基于id3的
frame改进技术
20
24
31
10
+
1
0
0
0
10
65
75
55
10
++
0
0
0
说明:绝对支持度:指包含频繁访问页组的最小用户会话个数
|fg
i|:长度为
i的频繁访问页组的数目
*:表示发现的频繁访问页组是用户不感兴趣的
+:表示发现的频繁访问页组是用户较感兴趣的
++:表示发现的频繁访问页组是用户感兴趣的
上述数据表明,通过在web日志预处理阶段增加id3算法进行frame过滤步骤后,其日志数据预处理结果的质量比一般技术及frame改进技术都高,因此更大程度地提高了挖掘结果的兴趣性。而且由于算法本身的性质及在路径补充步骤中减少了提升站点结构这一步,因此也极大地提高预处理的效率,并由此搞高了整个web日记挖掘的效率。
4 总结
文中用决策树算法中的id3算法改进了frame过滤算法。经验证,在通过过滤原始日志数据中浏览器自动在显
示frame页面时向服务器请求的subframe页面,对存在frame页面的网站实施web日志挖掘算法时,基于id3算法的frame页面过滤技术进一步提高了对存在frame页面的网站实施web日志挖掘算法时的效率及挖掘结果的兴趣度。
5 参考文献
[1]. jiawei han, micheline kamber. data mining concepts and techniques.机械工业出版社
[2] 杨怡玲, 管旭东, 陆丽娜, 尤晋元. web日志挖掘预处理中的frame页面过滤算法. 计算机工程, 27(2): 76-77, 2001.
[3]. 朱明. 数据挖掘 中国科技大学出版社
[4]. gordon s. linoff, michael j.a.berry. .mining the web:transforming customer data into customer value 电子工业出版社