摘 要 通过分析当今说话人识别系统中常用的语音特征和基本的说话人识别方法,本文采用多门限多判决的动态时间规整算法作为识别方法,并提取出美尔频率倒谱及其差分、线性预测倒谱及其差分、基音周期、短时谱的临界带特征矢量和子带能量倒谱等多种语音特征进行互相组合,找出了相应于该识别方法的最优特征组合。
说话人识别;动态时间规整;特征组合
1 引言
说话人识别是语音识别的一个分支,在公安侦察、声控系统、医疗诊断、电子金融业务等方面有着广泛的应用前景。它和语音识别的区别在于,它并不注意语音信号中的语义内容,而是希望从语音信号中提取出个人的信息特征。从这点上说,说话人识别是企求挖掘出包含在语音信号中的个性因素。而语音识别是企求从不同人的语音信号中寻找共同因素。
通过分析前人对说话人识别的工作总结,为了进一步提高识别率,本文采用了多门限多判决的改进的动态规整(dynamic time warping ,简称dtw)方法进行说话人辨认,在增加少量运算代价的情况下,新方法改善了辨认系统的性能。
说话人识别是企求挖掘出包含在语音信号中的个性特征而后进行识别。WwW.11665.coM一般说来,单一参量很难使系统性能可靠,因为它不能充分描绘说话人的个体特征,其中会包含语义信息,或只是说话人特征的某一方面,所以在实际应用中往往要采用不同参量的集合。因此,本文将提取的多种特征进行不同的组合,试图寻找出相应于上述识别方法的具有较高识别率的语音特征组合。
2 语音特征的提取
在提取特征之前,所采集的语音信号必须经过预处理,一般包括预加重、加窗和分帧。为减少计算量提高计算精度,在预处理后要进行端点检测。本文利用语音短时能频值
[5]作为端点检测的参数,这种方法相当于在传统方法中,以背景噪声的短时能频值为基准对绝对门限值作调整,结果表明能频值端点检测的方法适应环境的能力比较强,准确率较好
[5]。
本文利用了“短时分析技术”
[1]提取了以下几种常用特征:16维的美尔倒谱参数mfcc及其差分系数△mfcc、12维的线性预测倒谱参数(lpcc)及其差分系数△lpcc、12维的美尔线性预测差分倒谱系数
[1](lpcmcc)、基音周期p及其差分△p、18维的短时谱的临界带特征矢量
[1](本文用gl表示)和子带能量倒谱
[6](sub-band mfcc,本文用sbc表示)系数及其差分(△sbc)。其中,本文是采用自相关方法提取的基音周期,并运用了二次平滑算法
[1]去除了基音轨迹中的“野点”。在提取子带能量倒谱时,本文是将语音信号按照mel刻度在树结构中的多级子带分解为11个子带信号进行计算的。
3 说话人识别方法
3.1 动态时间规整算法
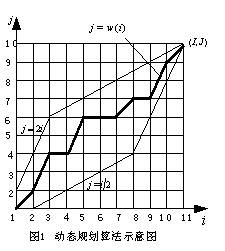
动态时间规整匹配是基于动态规划的思想,解决了发音长短不一的匹配问题,把时间规整和距离测度计算结合起来的一种非线性规正技术,是语音识别中出现较早、较为经典的一种算法。设测试语音参数共有 i 帧矢量,则测试语音模板的特征矢量序列为x=(x
1 、x
2 、…、x
i),参考语音参数共有 j 帧,则参考模板的特征矢量序列为y=(y
1 、y
2 、…、y
j )。且 i≠j,则动态时间规整就是要找到一个时间规整函数 j=w(i) ,将测试矢量的时间轴 i 非线性地映射到参考模板的时间轴 j上,并使该函数 w 满足下式:
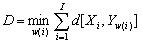
(3.1)
其中
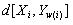
, 是第 i 帧测试矢量x
i 和第 j 帧模板矢量 y
j 之间的距离测度,一般这个距离测度采用欧氏距离的平方,如(3.2)式所示。d则是处于最优时间规整情况下两矢量的距离。
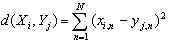
(3.2)
其中 x
i=( x
i1, x
i2,x
i3 ,…,x
in), y
j =( y
j1,y
j2 ,y
j3 ,…,y
jn ),n是特征矢量维数。
实际应用中,dtw一般采用动态规划技术(dp)来实现
[1]。动态规划是一种最优化算法,其原理如图1所示。将测试模板的各帧 i=1,2,......,i 作为二维直角坐标系的横轴,参考模板的各帧号j=1,2,......,j 作为纵轴。通常规整函数w(i) 被限制在一个平行四边形内,如图1,它的一条边的斜率为2,另一条边的斜率为1/2 。规整函数的起始点为 (1,1),终止点为(i,j) ,即w(1) =1,w(i)=j 。 的斜率为0、1或2;否则就为1或2。这是一种简单的局部路径限制。 求最佳路径问题可以归结为满足局部路径约束条件,使得沿路径的累积距离最小。
搜索该路径的方法:从(1,1) 点出发,可以展开若干条满足局部路径约束条件的路径。假设可以计算每条路径达到 (i,j)点时的总的累积距离,具有最小累积距离者即为最佳路径。
这个最小累积距离即为测试语音模板与参考模板语音之间的距离。则与测试模板距离最小的参考模板对应的说话人即判为识别结果。
3.2 改进的多门限多判决的动态时间规整方法
很显然,在模板库中总的词条数目不变时,增加模板的数量会提高识别率,但是模板数目的增加也会带来系统响应速度变慢的问题。因此,本文在说话人辨认系统中采取了多门限多次判决方法
[2],系统参考模板库中共存有四套模板。输入语音构成的测试模板先跟第一套模板进行匹配,求出与每个模板的最佳匹配距离,距离最小者作为候选输出。设定一个拒绝门限,若最小匹配距离也大于该门限,则表明该输入语音不在语音库范围内,停止下一步匹配,结果判该输入语音对应的说话人为库外人员。另外再设一个接受门限,若匹配距离小于该门限,则候选输出为正式的输出;否则,再进行第二轮匹配,即与第二套模板进行匹配.这样一直到第四套模板,如果此时还没有得到理想的输出,则可综合评价四次匹配结果,得出最后的输出结果。此外,为了减少多轮匹配的计算量,定义一个差别阈值
[2],在每轮匹配结束后,计算最小匹配距离与其他模板匹配距离的差别,若所有的差别均大于差别阈值,则表明输入模板与候选输出模板较其他模板有很大的相似性,可以作为正式的输出。若仍有模板的差别小于差别阈值,则表明这些模板与候选输出模板之间还可能存在混淆,需待下一轮匹配进行澄清。因此在下一轮匹配时,只需计算输入语音与这些模板之间的匹配距离,而将其他模板排除在外。
本文的拒绝门限设定为在两个参考模板中对候选输出者的语音进行模板匹配得到的累积距离d
r 的倍数,即
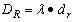
(λ>1 )为拒绝门限。接受门限则设定为:
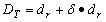
,其中 0<σ<1, 是根据使用不同的特征矢量分别设定的。
由于人的语音会随着时间的变化而变化,而且会受到健康和感情等因素的影响,所以随着训练时间与使用时间间隔的加长,系统的性能肯定会有所下降。为了维持系统性能,一种解决办法是在训练时所取得语音样本来自不同的时间,比如相隔几天或几周,但这样往往难以做到。因此可以使用另一种方法,在使用过程中不断更新参考模型,即是在每次成功的识别以后,把当时说话人的语音提取得到的特征按一定的比例加入到原来的参考模板中,以保证对使用者说话状态的跟踪
[1]。
4 识别实验
4.1 数据来源及数据的预处理
由于目前尚无说话人识别的标准数据库,本实验所用的语音数据均在普通实验室环境下,采用sound-blaster16声霸卡和耳机自带话筒录音采集,录音软件为sonic foundry sound forge6.0。录制了15个人(包括10男,5女),5秒钟的语音。本实验的采样频率为11025hz,量化值为16bit。录音数据按帧长256点,帧移为128点,预加重为
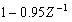
,加汉宁窗逐帧提取语音特征。所用的语音特征是第2节中提取的语音特征进行不同的组合所得到的特征组合。
4.2 文本相关说话人辨认系统的实现
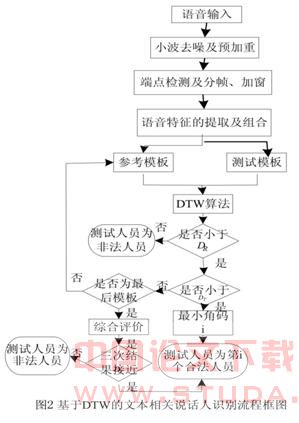
本系统采用动态时间规整方法作为文本相关的说话人识别方法,其识别流程图如图2所示,其中 和 分别为拒绝门限和接受门限。实验都是采用matlab6.5作为开发环境,分别针对不同的特征矢量组合做了三类实验。说话人辨认系统的目的是利用机器自动辨认出待识别的语音是来自待考察的人员中的哪一个,判断待识别语音所属的说话人的身份。
实验一:每人每遍说相同内容的一段5秒内的语句,语音材料为朗读报刊杂志中的一到两句话,共录制4遍,不同的人说不同的语音内容。先分别单独使用提取出的语音特征作为特征矢量用dtw算法进行识别,而后将其组合成不同的组合特征矢量进行识别,以正识率为评价标准。
实验二:每人每遍说相同内容的一段5秒内的语句,语音材料为朗读报刊杂志中的一到两句话,共录制4遍,不同的人有说相同的语音内容。
实验三:每人每遍说不同内容的一段5秒内的语句,语音材料为朗读报刊杂志中的一到两句话,共录制4遍,不同的人有说相同的语音内容。
4.3 实验结果及分析
表1 说话人辨认系统中不同语音特征的比较识别结果
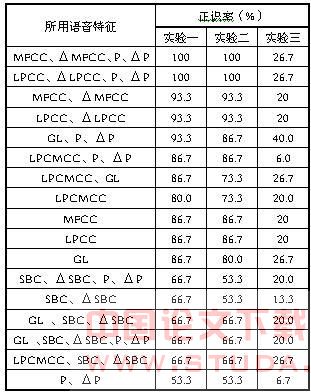
通过以上三个实验,其所得的结果如上表1所示。由表1所示的实验结果可以看出,单独使用说话人的语音特征所得的识别结果不如组合使用时的效果好。而在组合使用特征时,mfcc及△mfcc同p及△p组合和lpcc及△lpcc与p及△p的组合,收到的效果最好。这是因为美尔倒谱参数mfcc充分利用了人耳感知系统特性计算出来的特征参数,符合人耳听觉特性,并且能很好的反映语音内容;同时基音周期p描述了说话人个性语音中最基本的信息,而△mfcc和△p则分别是反映了人耳听觉特性的动态特征和基音周期变化的动态特征,这样将说话人语音的静态特征与动态特征相互组合进行文本相关的说话人辨认,效果最为理想。而lpcc及 lpcc与p及 p的组合特征,是结合了反映说话人声道的静态及动态特性的线性预测倒谱及其差分与基音周期的动静态特征,同样在说话人辨认实验中达到了理想的识别结果。
本实验还利用了短时谱分析得到的短时谱临界带特征矢量同p及△p进行组合。在辨认系统中也得到了较好的效果,正识率达到了93.3%。而子带能量倒谱的效果并不如理想中好,原因可能是子带的分段数过少,提取过程还不够精确。
由辨认实验三可以看出,当说话人在参考模板和测试模板中说不同内容的语音时,各种特征组合所得到的识别结果都不理想,说明用动态时间规整算法进行文本无关的说话人识别,效果并不理想。
同时,我们发现当拒绝门限或接受门限设得过高时都会使错误接受率降低,但这样就增高了错误拒绝率,这对于安全系数要求不高的场所(例如,大量使用者利用电话访问公共数据库)会造成用户的不满。因此应该根据不同的使用场合设定门限值。而说话人辨认系统的识别率不仅与门限设置有关,还与识别的人数多少有关,人数越多,识别率越低,所用的计算时间也逐渐增长。
5 结束语
由上面所得的实验结果可以证明,利用改进的多门限多判决dtw法作为说话人识别方法,在一定程度上提高了说话人识别系统的识别率。并且利用多种语音特征组合作为识别的特征矢量时,也获得了较好的识别效果。找出了几种具有较高识别率的特征组合,为进一步研究说话人识别方法提供了更多的语音特征组合方案。
参考文献
[1] 赵力.语音信号处理[m].北京:机械工业出版社,2003.
[2] 程利忠, 张宪民. 基于语音识别的说话人身份辨识系统.上海交通大学学报,1998,32(9):86~89.
[3]李蕴华.将倒谱参数与基音信息有效结合进行说话人辨认[j].信号处理, vol.16 , 2000. 3 : 85-89 .
[4] zhangwan
-feng,wu zhao
-hui,yangy ing
-chun,ma zh i
-you, feature combination for speaker identification[j] , vol . 21 , 2003 . 3 : 10-15.
[5] 刘永红.说话人识别系统的研究[d].研究生学位论文,西南交通大学,2003.4
[6] 王金甲.噪声环境下鲁棒性文本自由说话人辨认系统的研究.[硕士学位论文],秦皇岛:燕山大学信息科学和工程学院,2003