[ժҪ] ���IJ������ڵ�������Ӧ���У�����web�ھ�������Ч�ؽ��û����ʹ����е����ݼ�¼����־�ļ��У�������־�ļ�������Ч�ط������ھ�����apriori�Ľ��㷨ft���������㷨���ҳ��Ե�������ϵͳ��ָ�����õĹ������ɡ�
����[�ؼ���] �������� �����ھ� ��־�ھ� ֪ʶ���� �˹�����
�������ŵ�������ķ�չ����ҵ������Խ��Խ�࣬���������ݻ��۵�һ���̶�ʱ����Ȼ�ᷴӳ��һ�������ԵĶ�����Ҳ����˵����ҵ�ĺ������ֲ�����̬�����ӡ��ǽṹ�����������̺��п���Ϊ�����õĹ��ɡ���ˣ���������ϣ��ʹ��һ�ּ����������ھ�����м�ֵ�Ĺ��������γɶ���ҵ�ļ����;�Ӫ��ָ���������ھ����ǿ��������ھ���Щ���ɵ�һ����Ч���ߡ�
����web�а����ķḻ�Ͷ�̬�ij�������Ϣ���Լ�webҳ��ķ��ʺ�ʹ����Ϣ��Ϊ�����ھ��ṩ�˷ḻ����Դ����ζ�web�е����ݽ�����Ч����Դ��֪ʶ���֣���web�ھ���Ҫ��������⡣
����
����һ��web��Ϣ���ݵ�����
����
������ͳ�����ھ����Ϣ���������ݿ��еĽṹ�����ݣ���web��Ϣ�����ǰ�ṹ����ǽṹ����,������������: һ�Ǵ��ģ����������Ϣ��������Ϣ�ֲ��㷺���������ʡ���̬����ϢԴ��web�������ݵĸ��¡������ٶȼ���, web�ϵ���Ϣ�����������صġ�δ֪�ġ�������Ϣ���зḻ���ں��������漰������ḻ����Ϣ����,���̺��ŷ���ҳ�桢·����ʱ�䡢�û�ip��ַ����ЩDZ�ڵķ�����Ϣ��
����
�������������ھ�web�ھ���
����
����1.�����ھ�
���������ھ��ֳ����ݿ��е�֪ʶ���֣����������ѱ����ݿ�����㷺�о���wWW.11665.coM���������ݲֿ��������ݿ�Ļ����ϣ��Ӵ����ġ�ģ���ġ��������������ȡ�����ݼ���Ҫ�ĵ����ױ��˹��������Ե�֪ʶ����Ϣ�������ھ����漰���ݿ⡢�˹����ܡ������硢Ԥ�����ۡ�����ѧϰ��ͳ��ѧ�ȶ�����ؼ��������ݿ��е�֪ʶ���֣�kdd���ǴӴ�����������ȡ�����ŵġ���ӱ�ġ���Ч�IJ��ܱ����������ģʽ�ĸ��������̡�ģʽ���Կ�����������˵��֪ʶ�������������ݵ����Ի�����֮��Ĺ�ϵ���Ƕ����ݰ�������Ϣ�������������
����2.web�ھ�
����web�ھ��Ƕ������ھ��һ���µķ�չ��Ӧ�ã�����ͬ�ڴ�ͳ�������ھ�����Ҫ�������ڴ�ͳ�������ھ�Ķ�����������ݿ��еĽṹ�����ݣ������ù�ϵ���ȴ洢�ṹ���ھ�֪ʶ����web�ھ�Ķ����ǰ�ṹ����ǽṹ��������
����web�ھ���ǴӴ�����web�ĵ���web��з��֡���ȡ����Ȥ�ġ�DZ�ڵ�����ģʽ�������ġ�����δ֪�ġ�DZ�ڵ���Ϣ�����������ھ��ı��ھ�ý���ھ�Ϊ���������ۺ����ü�������硢���ݿ������ݲֿ⡢�˹����ܡ���Ϣ��������Ϣ��ȡ������ѧϰ��ͳ��ѧ���������ۡ����ӻ������������ѧ����Ȼ��������ȶ������ļ�����������ͳ�������ھ�����web���������web�ھ��Ϊ��web�����ھ�web�ṹ�ھ��webʹ�ü�¼�ھ�����ͼ��ʾ��
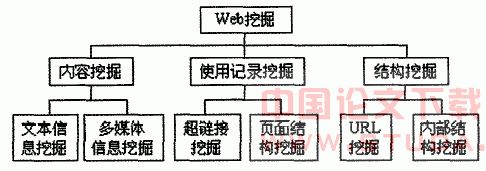
����ͼ web�ھ�ķ���
����
������������web��־�ھ���㷨
����
����web��־��¼���û����ʵ���Ϣ�������û��ķ��ʷ�ʽ������ʱ�䡢�����������û�ip��ַ���������ļ���url http�汾�š������ֽ���������ҳ��url�ȡ�
����1.�����붨��
����web��־�ļ�����һ����¼��ɵģ�һ����¼ʵ���ϼ�¼�����û���webҳ���һ�η��ʡ�
��������1����������i��web��־��һ����¼����i={i1,i2,��,im},����ij(1��j��m)��ij�û�����һ����Ʒ�����ݣ�ÿ�η���һ����Ʒ������������Ʒ��š�����ʱ�䡢���ʴ������ͻ��š��ͻ�ip��ַ�����ݣ��ƴ�������Ϊ�����ti��iΪi��һ���Ӽ���d={t1,t2,��,tn}�ǹ���ti�ļ��ϣ���x��i��y��i��x��y =�棬���¼x=>yΪ�ڼ���d��x��y������Ĺ���
��������2֧�ֶȣ����x=>y��t�е�s%���������x��>y��֧�ֶ�Ϊs%����
����s% =(|{t|t���x,y}|/|t|)��100%
����֧�ֶ�s%��ʾx=>y�г��ֵ��ձ�̶ȡ�
��������3���Ŷ�c%
����c%=(|{t|t���x,y}|/|{t|t���x}|)��100%
�������Ŷȱ������ǹ����ǿ�ȡ�
��������4Ƶ��ģʽ�����ڸ�����֧�ֶȵ�ģʽx=>y��ΪƵ��ģʽ��������������t��һ��������Ĺ�������
����2.�㷨����
��������fp��������Ƶ��ģʽ������frequent-pattern growth���㷨��������������ھ��Ϊ��������ʵʩ���������ṩ����С֧�ֶȺ���С���Ŷ��ҳ����е�Ƶ�����������������Ƶ��������������Ĺ�������
������1��fp�������㷨�ľ����㷨�������£�
���������������ݿ�d����С֧�ֶ���ֵmin_sup
�������d�е�����Ƶ���
��������1�����²���ɨ�蹹��fp������
������ɨ���������ݿ�dһ�Ρ��ռ�Ƶ����ļ���f����֧�ֶȡ���f��֧�ֶȽ��������ΪƵ�����l��
�����ڴ���fp�����ĸ��ڵ㣬�ԡ�null����ǡ���d��ÿ��trans,ִ�У�
����ѡ��trans�е�Ƶ�����l�еĴ���������������Ƶ�����Ϊ[p��p]������p�ǵ�һ��Ԫ�أ�p��ʣ���Ԫ�ر�������insert_tree([p��p] ,t)���������t����Ůnʹ��n.item��name = p.item��name����n�ļ�������1������һ���½ڵ�n���������������Ϊ1�����ӵ����ĸ��ڵ�t����ͨ���ڵ����ӽṹ�������ӵ�������ͬitem�Cname�Ľڵ㡣���p�ǿգ��ݹ����insert_tree��p,n����
��������2procedure ft_growth(tree,��)
����if tree������·��p then
����for p�нڵ��ÿ����ϣ������£�����ģʽ�¡Ȧ�����֧�ֶ�support=���нڵ���С֧�ֶȣ�
����else for each ��i��tree��ͷ��{
��������һ��ģʽ��=��i�Ȧ�����֧�ֶ�support =��i��support��
��������µ�����ģʽ����Ȼ����µ�����fp����tree�£�
����if tree�¡٦�then
��������fp_growth(tree��,��)��}
������2������Ƶ�����������Ҫ������β�������Ƶ�����������һ����ά��web��־�����ļ���һά����Ʒ�ţ�����������Ʒ���ֱ��־Ϊt1��t2��t3����һά������Ʒ�ķ��ʴ�����Ϊ�������ֱ��־Ϊinterview1��interview2��interview3��interview4��interview5��������min_sup=0.3��minconf =0.5,��1��������ά���������ݿ⣬��2��������һάƵ�������3�������Ƕ�άƵ�����
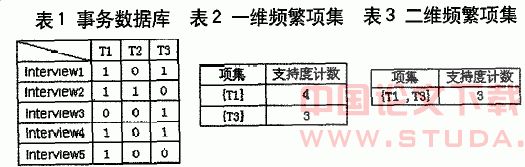
����
�����ġ�������
����
�������������һ�ֻ�����־��web�����ھ����Ե�������ϵͳ���н�ǿ����ʵָ�����塣web��־�ھ����õ��Ľ���������������վ�����ܺͰ�ȫ��,Ҳ������Ϊ�Ż�վ�����˽ṹ��ҳ��֮��ij����ӹ�ϵ������,Ҳ����web�Ͻ����г������Ϳ�չ��������������,Ҳ������Ϊ��վΪ�û��ṩ���Ի�����������ܻ�webվ������ݡ�