摘 要 包含有大部分或全部源码信息的软件发行版本的普及,比如易被反编译成源码的java字节代码,增加了软件被恶意逆向工程攻击的可能。文章介绍了面向对象语言的类分裂混淆方法,同时也给出了混淆技术的定义、分类和评判标准。
关键词 逆向工程;代码混淆;软件保护;类分裂
1 引言
计算机软件的安全一直是软件企业和相关研究领域的关注重点,当前存在的软件保护技术分别有硬件辅助保护、序列号保护、加密保护、服务器认证、防篡改以及代码混淆等。随着java语言、逆向工程的迅速发展和普遍运用以及恶意主机对软件的逆向分析等突出安全问题的不断涌现,使得代码混淆,这一新的保护软件安全的技术正越来越受到人们的重视。
2 代码混淆的定义和分类
2.1 代码混淆定义
给定一个程序p、策略t,经过混淆变换后得到程序p' (见图 1)。wWW.11665.Com此过程称之为混淆变换,如果对程序进行一种功能保持的变换,变换后的程序拥有和原始程序相同的功能。更确切的说法应该包含以下两个条件:①如果p出错终止或终止失败,p'不一定终止。②p和p'在正常终止情况下,p'必须产生与p相同的输出。
所不同的是经过转换的p'相较p更难于被静态分析等逆向工程方法攻击,即使被反编译,生成的程序也难以被人阅读和理解。
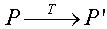
图1 代码混淆
2.2 代码混淆分类
根据混淆对象和对其进行操作的差别,可将代码混淆技术分为布局(layout)混淆、控制(control)混淆、数据(data)混淆、预防(preventive)混淆等几种。
(1)外形混淆。该类混淆主要包括对程序中的变量名、常量名、类名、方法名称等标识符作词法上的变换改名和删除程序中与执行无关的调试信息、注释、源码格式等。
(2)控制混淆。该类混淆的目的是使得攻击者对程序的控制流难以理解。主要包括打乱某段代码本身逻辑关系的聚集混淆(aggregation transformation)、把相关语句分散到程序不同位置并实现某项功能的次序混淆(ordering transformation)和隐藏真实执行路径的执行混淆(computation transformation)等。
(3)数据混淆。数据混淆的对象是程序中的数据域。它可细分为相关数据的储存(storage)与编码(encoding)方式的混淆、组合和拆分数据的聚集(aggregation)混淆、位序重计的次序(ordering)混淆等。
(4)预防混淆。与前述混淆类型针对恶意用户不同,预防混淆主要利用一些专用反编译器的设计缺陷,以使这些反编译器难以反向还原混淆之后的代码。例如,反编译器 mocha 对于 return 后面的指令不进行反编译,hosemocha 就是专门针对此缺陷,故意将代码放在 return 语句后面,从而使反编译失效。
2.3 类分裂
介绍完代码混淆的分类后,接下来我将就面向对象语言中的一种混淆技术:类分裂(class splitting)进行说明。首先对类分裂进行定义:类分裂是将一个初始(原)类用两个或两个以上的类来替换的混淆方法。对类分裂进行叙述前,我们规定以下相关使用术语的意义:
p: java程序
classes(p): p中一般类的集合
interfaces(p): p中接口类的集合
c
t: class或interface中的任意类
methods(c
t): c
t中的成员函数的集合
field(c
t): c
t中的成员变量的集合
注:methods(c
t),field(c
t)不包括从父类继承的成员函数和成员变量,而只包括:①当前定义类中新定义的成员函数和成员变量。②当前定义类所覆盖的其父类的成员函数。
依赖(depends)关系的定义:
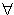
m,n methods(c
t),如果存在m调用n,则(m,n) ∈ depends
and
m∈methods(c
t),
f∈field(c
t),如果存在m使用了f,则
(m,f) ∈ depends
为了便于用例的书写,特做说明,图2左列和右列的符号实际上表示同一类。
c
c
t
c1
c
t,1
c
t,1
c
t,2
图2
其次,由于类分裂的方法很多,为了叙述方便,我们假设将类c
t分裂成两个新类c
t,1和c
t,2,公式如下:
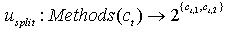
分裂函数u
split代表了这么一个分裂过程:原来的类的成员(成员函数或成员变量)被拆分到某个或是两个新类中。
分裂函数的选择必须考虑到成员函数之间或成员函数和成员变量之间的依赖关系,这是决定分裂函数是否有效的重要标准。下面的程序中,初始程序中的类c
t不能被分为混淆后的程序中两个毫无继承关系的新类,而应分裂为具有继承关系的类c
t,1和c
t,2。可以使用另一种表达方式描述:初始程序中类c
t的m2成员函数调用了m3成员函数,因此我们不能将m2作为c
t,1的成员函数,m3作为 c
t,2的成员函数,而c
t,1和c
t,2两者间无继承关系。而应将m2 作为子类c
t,2的成员函数,m3作为父类c
t,1的成员函数。且成员函数m3不需要修改,m3依旧调用m2。
如果出现这种情况:由于初始程序中的类设计本身存在缺陷,导致该类实际等同于多个类的组合。在此前提下,可以将初始类分裂为毫无继承关系的两个或两个以上新类。
将类分裂为具有继承关系的新类的方法产生了大量有效的分裂函数,这是因为这种分裂方法的约束条件非常简单且只具有惟一的限制:成员函数和成员函数所使用到的成员变量必须在同一类中定义,而这个类必须是定义成员函数的类。用公式表述如下:
m∈methods(c
t):
if c
t,1∈ u
split(m),then
n∈methods(c
t)):depends(m,n)→c
t,1∈ u
split(n) and
f∈fields(c
t)):depends(m,f) →c
t,1∈ u
split(f)
原则的体现如同下面所示类分裂混淆例子所示:成员函数m3调用了成员函数m4,因此将m3和m4定义为类c
t,1的成员函数。由于分裂函数u
split将m4函数分配给了类c
t,2,类c
t,1的成员函数m4其实只是一个虚假的程序段(函数),它使恶意逆向工程人员以为调用的是c
t,1的成员函数m4。但实际情况是:程序运行期间c
t,1的成员函数m4将不会被调用,它将被c
t,2的m4成员函数所覆盖。同时,类c
t,1中构造函数用到的成员变量i,d都在类c
t,1定义,类c
t,2中构造函数用到的成员变量o则在类c
t,2定义。
接着,当新类产生后,必须要对原有的类型声明进行替换,主要包括:
●成员函数的参数,成员变量和本地变量的类型声明由c
t变为c
t,1和c
t,2代替,程序中是c使用c1和c2代替。
●原类构造函数的调用由c
t变为c
t,2,程序中用c2替代c,这是防止动态类型转换的一个简单替换。
初始程序 混淆后的程序
class c { class c1 {
private int i; private int i;
private double d; private double d;
protected object o; public c1() {
public c() { i=5;
i=5; d=1.0;
d=1.0; }
o=new object(); public c1(int iarg,double darg) {
} i=iarg;
public c(int iarg,double darg) { d=darg;
i=iarg; }
d=darg; public boolean m1() {
o=new object(); 混淆变换 return i < 0;

} }
public boolean m1() { protected void m3(int iarg) {
return i < 0; i=iarg;
} m4(new object());
public void m2() { }
d=3.0; public void m4(object obj) {
m3(3); o=obj.getclass();
} }
protected void m3(int iarg) { }
i=iarg; class c2 extends c1 {
m4(new object()); protected object o;
} public c2() {
public void m4(object obj) { super();
o=obj; o=new object();
} }
} public c(int iarg,double darg) {
class d { super(iarg,darg);
void n() { o=new object();
c c=new c(); }
if (c.m1) {…} public void m2() {
c.m2; d=3.0;
c.m4; m3(3);
} }
} public void m4(object obj) {
o=obj;
}
}
class d {
void n() {
c2 c=new c2();
if (c.m1) {…}
c.m2;
c.m4;
}
}
3 代码混淆的评判指标
程序混淆效果通常从强度(potency)、耐受性(resilience)、开销(cost)、隐蔽性(stealth)等 4个方面来评估:
(1)强度。指混淆变换后的程序相对原始的程序对恶意用户理解程序造成的困难程度或复杂度。
(2)耐受性。指混淆变换后的程序对使用自动去混淆工具进行攻击的抵抗度。其抵抗度大小与前述标准之一的强度的大小无直接联系,甚至可能出现某些强度很高的混淆变换对自动去混淆工具的抵抗能力却很差的情况。
(3)开销。指经过混淆变换后的程序在执行时由变换所带来的额外的执行时间和所需存储空间的开销。
(4)隐蔽性。耐受性好的混淆变换不容易被自动去混淆工具所去除,但却可能很容易被攻击者的人工分析识破。特别是,如果一种变换所引入的代码和原始程序有较大的差异性,就会轻易地被攻击者识破,因此应尽力使用与原代码相近的语法结构等来加强隐蔽性。
4 结语
代码混淆的目的是防止对软件的逆向分析,从而有效保护软件知识产权。它通过改变程序本身,使其转换为极难理解和分析的新程序,最终让恶意攻击者在必须耗费其所不能承受的代价(时间或其它方面)面前,放弃对软件的分析来实现。但代码混淆技术作为一种新的软件保护方法,在理论基础、技术成熟度等方面依旧存在许多不足,这也将是代码混淆技术下一步要解决的问题。
参考文献
[1] c. collberg,c. thomborson,and d . low. a taxonomy of obfuscating transformations. technical report 148,july 1997
[2] c. s. collberg and c. thomborson. watermarking,tamper-proofing,and obfuscation- tools for software protection. ieee transaction on software engineering,28(8):735-746,aug,2002
[3] h. chang and m. atallah. protecting software code by guards. in proceeding of the acm workshop on security and privacy in digital rights managements,pages 160-175,nov. 2001
[4] c. wang. a security architecture for survivability mechanisms. phd thesis,university of virginia,school of engineering and applied science,october 2000
[5] mikhail sosonkin,gleb naumovich and nasir memon. obfuscation of design intent in object-oriented applications. department of computer and information science polytechnic university 2003
[6] 罗宏,蒋剑琴,曾庆凯.用于软件保护的代码混淆技术.计算机工程,第32卷第11期,2006.7
[7] 宋亚奇.基于代码混淆的软件保护技术研究.硕士论文,西北工业大学,2005.6