[摘要] xml广泛应用于web数据的表示和交换,而海量xml数据的存储、处理对传统数据库提出了严峻的挑战,native xml数据库应运而生,本文重点讨论了nxd数据库数据存储的几个方面,指出其有待进一步研究的问题。
[关键词] xml native xml database 数据库
随着internet进入社会生活的各个方面,电子商务等的广泛应用,关系型数据库在处理信息的复杂化,多样化,差异化,灵活性,可读性等方面的不足日益明显。特别是目前web service的蓬勃发展,xml越来越多地活跃在数据交换和存储领域,其数据量指数级的增长,要求更有效的数据管理能力和更快、更精确的查询,而这是传统关系型数据库领域所没有涉及到的,可以说是数据库发展的一个分水岭。nxd(native xml database)技术的出现给数据库研究界带来了巨大的机会,如何高效存储管理xml数据也自然成为研究的热点。
一、xml和xml数据库
xml是the extensible markup language(可扩展标识语言)的简写, 具有扩展性、自描述性、自相容性等优点,成为internet上数据表示和数据交换的标准。
对xml文档进行存取管理和查询的xml数据库分为两类:支持xml数据库管理系统(xed)和纯xml数据库管理系统(nxd)。xed(xml enabled database)是在原有关系数据库基础上扩展了xml支持模块,通过适当的xml api对xml文档进行查询和修改,完成xml数据和关系数据库之间的格式转换和传输。WwW.11665.CoMnxd(native xml database)则出现在xml数据处理领域内,是专门设计用于存储和管理xml文档的数据库,它以xml文档作为数据库的存储单元进行操作和管理,保持xml文档的树形结构,省掉了xml文档和传统数据库的数据转换过程。
二、nxd的概述
1.nxd定义
ronaldbourret在“xmlanddatabases”一文中给出有关nxd的定义。一个纯xml数据库是指:(1)相对于xml文档中的数据,定义了xml文档的逻辑模型,并且按照该模型来存储和检索文档。这样的模型至少应该包括元素、属性、pcdata以及文档顺序。(2)就像关系数据库以行作为表的逻辑存储基本单位一样,nxdbms以xml文档作为nxd的逻辑存储基本单位。(3)不要求有任何特殊的基本物理存储模型,它可以建立在关系的、层次的或面向对象数据库之上,或者使用诸如索引文件、压缩文件此类的专门存储格式。
但在很多方面,xml应不同于关系模型和面向对象模型等数据模型,将xml映射到另一种数据模型常常引起“阻抗失配”,并导致功能和性能上的局限。因此,业界提出nxd必须直接存储和处理xml数据。
2.nxd特性
纯xml数据库的特性有:(1)文件集(document collections):支持集合(collection)的概念,集合级别上的查询,修改操作都会反映到集合内的每个文档中。(2)查询语言(query languages):目前主流的是xpath,但其存在不能分组,排序和连接等缺陷,因此 xquery作为xpath的替代品,有希望成为纯xml数据库的专用语言。(3)更新和删除(updates and deletes):nxd 绝大多数产品在这方面仍是薄弱环节。(4)事务、锁定和并发(transactions,locking,and concurrency);支持事务处理。锁定通常是对整个文档的,所以多用户并发性相对较低。(5)纯xml数据库提供良好的编程接口。(6)能够高效而精确的还原xml文档。
三、nxd数据存储结构
1.物理存储
将元数据、xml数据、索引和统计数据如何放置在物理磁盘上永远是一个挑战性的问题,因为底层的存储表达对上层的查询处理和优化有着重要的性能影响。
纯xml数据库在物理上存储xml文档主要有三种方案:
(1)字节流方式:即将xml数据转换为字节流,这种方式将文档转换为字节流,然后将其存储在文件系统的文本文件中或存储为数据库的blob字段中,然后在这些文件或字段上面加一些索引,通过这种方式来提供某些数据的功能,当存储和检索整个文档时,这种方式效率较高,并且能够精确地再现原来的xml文档,但缺点在于任何一次查询文档时都必须通过分析器处理后才能获得结构信息。
(2)元模型方式:即按照某种物理模型存储xml文档,这里模型的不同,分为两种方案,一种是采用现有的关系数据库或面向对象数据库作为xml数据的存储库,在重组文档片段或不同文档时比较快,但在逻辑层和物理层的数据需要经过转换,因而会降低处理效率。另一种是为xml数据库设计专有的存储方案,如 infonytedb采用的pdom方式就是首先将文档转化为dom结构,然将其映射到一些特殊的文件中。这种方案能够以一种比较自然的方式来存储xml数据,避免物理层和逻辑层数据之间转换,但由于采用全新的存储方案,技术不够成熟。
(3)混合型,这种方式又可以细分为两种类型:冗余型和杂交型。冗余型是指每份数据保持两份副本,一份基于文本方式存储,一份基于模型存储。这样可以同时利用两种方式的优点,但是两份数据很可能处于不一致的状态,且更新效率较低。杂交型存储方式中规定一个数据单元,粒度大于数据单元的部分以元模型方式存储,否则以字节流方式存储。
在实际的纯xml数据库中用的比较多的是基于元模型的方式和杂交方式 。
2.数据模式
在传统的关系数据库中,模式严格地约束着数据的类型、操作和结构,数据完全对应于模式,数据的插入、查询、更新和存储都必须遵循模式的定义。而xml数据具有半结构化的特征,数据与模式信息之间并不具有完全对应的关系,此时模式仅仅是作为查询或者了解数据的一个说明,并不具有约束数据的功能。因此,如何在纯xml数据库中发挥xml模式的作用是一个需要研究的问题。
3.存储粒度
xml数据是一棵由各种节点组成的树,常见的节点包括元素(element)节点、属性(attribute)节点和文本(text)节点。但是nxd中,一条记录所对应的子树有多大、包含多少个什么样的节点,这是nxd的存储粒度问题。记录的粒度分为三种:(1)结点级:一个结点就是一条记录。(2)子树级:xml文档的一个片段(一个子树)对应一个记录。目前,有两种划分子树的方法:①根据物理块大小,使子树的大小与物理块大小相近,不需要文档模式信息的支持;②根据逻辑意义划分子树,使子树成为一个比较完整的逻辑单位,需要文档模式信息的支持。(3)文档级:一个xml文档是一条记录,文档是作为一个整体来操作的,不需要有dtd或xmlschema等模式信息的支持。
不同的粒度对存储空间和查询的支持各不相同。对同一个xml文档来说,记录的粒度越小,记录的数目就越多,记录之间的指针就越多,存储空间需要的也越多,从而记录的存储效率较低,但小粒度的存储方法使每个元素和属性,包括文本都可以被单独查询、修改或删除,且对其他文档结构影响最小,具有最大的灵活性,也无须利用文档的模式信息。记录的粒度越大,为了读取某一个节点需要读进的节点数就越多,更新时效率就越低,但是大粒度的存储方法不需要存储过多的逻辑指针和物理指针,能够节省存储空间,且重构整个文档会比较快一些。因此,根据查询的要求如何确定xml数据的存储粒度也是一个挑战性的问题。
4.存储顺序
如果nxd中存储xml文档的记录粒度是狭义的节点或者子树,那么这些记录在物理空间中的组织方式就是记录的存储顺序问题,存储顺序是指记录在物理上的相邻关系。记录的存储顺序一般有以下几种:(1)深度优先顺序存储,这是最常见的存储顺序。(2)广度优先顺序存储。(3)按某个条件簇集存储,将满足某个条件的所有记录存储在同一个物理块内或物理上相邻的物理块内。对于xml文档来说,将记录的节点按类型相同的记录簇集存储,虽然在物理存储上破坏了节点的顺序,但有利于数据查询和更新。
根据存储粒度和存储顺序,将会产生以下几种具体的存储方法:①基于元素的深度优先(deb)方法;②基于子树的深度优先(dsb)方法;③基于元素的广度优先(beb)方法;④基于子树的深度优先(bsb)方法;⑤基于元素的同类簇集(ceb)方法;⑥基于子树的同类簇集(csb)方法。
如何确定nxd中记录的存储顺序,以及如何针对不同的应用选取不同的存储方法,或者是针对不同的查询选择不同的存储方法,这些都是挑战性的问题。
四、 应用
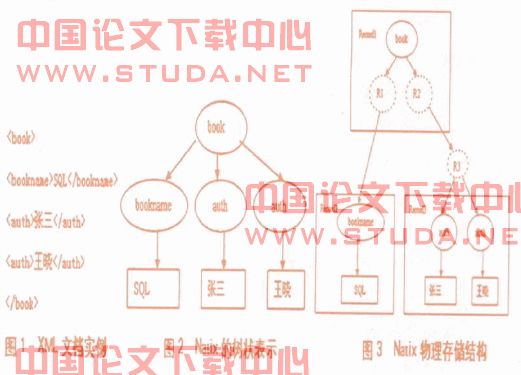
natix有着良好的存储系统,其记录内部的结点不完全是以字节流方式存储的文本。存储粒度上,natix有自己独特的划分子树的方式和分裂子树的算法 ,且记录子树的大小是可以动态确定的。物理上,xml文档映射成树的结构,在树结构中包含三种结点:(1)聚集结点:指树的内部结点。(2)文字结点:指页结点,内容可以是字符,图形,声音和视频等。(3)代理结点:实际上是记录之间联系的桥梁。下面以一个xml文档实例进行说明,见图1。xml文档映射的树状结构见图2。物理树的存储结构见图3。
如:
综上所述,纯xml数据库虽然在解决xml数据存储,高效处理和查询等方面较传统数据库有一定的优势,但是目前仍然存在很多具有挑战性的问题,这些问题给数据库研究人员提供了广阔的平台,也为我国在数据库研究方面赶超世界先进水平提供了机遇。相信随着xml更为广泛的应用于医疗、金融、电子政务、制造业及电子商务等领域, native xml数据库的明天更美好。
参考文献:
[1]amer-yahia s,cho s,lakshmanan l v s,et al.minimization of tree pattern queries.in:mehrotra s et al eds.proceedings of the 20th acm sigmod international conference on management of data. santa barbara,california,use.may 21-24,2001.new york:acm press,2001.497-508
[2]万常选:xml数据库技术[m].北京:清华大学出版社,2005 50-51