摘 要 本文提出了一种利用用户浏览页面集的内容信息和浏览行为信息,隐式地创建用户兴趣描述文件的方法。通过对用户浏览的web页面进行兴趣度分析,并与对用户浏览网页时的浏览行为分析相合,得到了用特征矩阵表示的用户兴趣模型。并采用层次聚类算法和 k-means 聚类算法相结合的综合聚类算法进行聚类,得到用兴趣分类树表示的用户兴趣模型。由于采用的是隐式创建用户描述文件的方法,减少了因用户参于而带来的系统噪声,保证了所创建的用户兴趣模型的准确性。
关键词 用户兴趣模型;浏览内容;浏览行为;兴趣分类树
人们正在寻求一种将用户感兴趣的信息主动推荐给用户,对不同的用户提供不同的服务策略和服务内容的服务模式,即个性化服务的信息方式 。
用户兴趣模型是个性化服务系统的关键部分,用户兴趣描述的准确与否直接决定着个性化推荐服务的质量好坏。本文提出了一种利用用户浏览页面集的内容信息和浏览行为信息,隐式地创建用户兴趣描述文件的方法。该方法以用户浏览web页面的内容信息和行为信息作为数据源,采用web挖掘方法分析得到较准确的用户兴趣描述,减少了由于用户参与而带来的系统噪声,保证了所创建的用户兴趣模型的准确性。
1 基于web浏览内容和行为分析相结合的用户兴趣模型
整个用户兴趣模型的创建过程包括web浏览内容分析和web浏览行为分析两部分,流程图如图1所示。wWW.11665.com
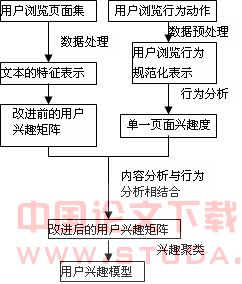
图1 用户兴趣模型创建流程图
web浏览内容分析,就是采用web聚类分析方法对用户已浏览的web页面集进行内容聚类,得到用户感兴趣的页面集;web浏览行为分析是对用户浏览页面时的行为信息进行分析,得到用户对单一页面的兴趣浓度。将二者相结合,就得到了用户感兴趣的主题类别及对每类主题的兴趣度,即用兴趣分类树表示的用户兴趣模型
2 基于web浏览内容的用户兴趣分析
本文中用户兴趣模型描述所基于的web浏览内容是指用户浏览页面的内容信息,它被用于基于内容的聚类分析。这些页面的内容信息主要来源于 web 服务器端,首先根据用户的浏览日志记录,得到单一用户的浏览历史页面 url,然后从数据库服务器中取出这些 url 对应的 web 页面,作为对浏览内容兴趣描述的数据源。
2.1 对浏览网页信息的数据预处理
与数据库中的结构化数据相比,web文档具有有限的结构,即使具有一些结构,也是着重于格式而非文档内容。此外,文档的内容是人类所使用的自然语言,计算机很难处理其语义。web 文本信息源的这些特殊性使得现有的数据挖掘技术无法直接应用于其上。这就需要对文本进行预处理,抽取代表其特征的元数据,作为文档的中间表示形式。
近年来应用较多且效果较好的特征表示法是向量空间模型(vector space modelvsm) 法。在vsm 中,将文本文档看成由一组词条
构成,对于每一词条
,根据其在文章中的重要程度赋予一定的权重
。因此,所有用于挖掘的页面文档都可以用词条特征矢量
表示。要将文本表示为向量空间中的一个向量,就先要将文本分词,由这些特征词作为向量的维数来表示文本,最初的向量表示完全是0、l形式,即,如果文本中出现了该词,那么文本向量的该维为l,否则为0。这类方法无法体现这个词在文本中的作用程度,所以0、l逐渐被更精确的词频代替,词频分为绝对词频和相对词频。绝对词频,即使用词在文本中的出现频率表示文本;相对词频为规一化的词频,其计算方法主要运用tf-idf公式,目前存在多种tf-idf公式,我们可采用一种比较普遍的tf-ldf 公式:
我们把用于挖掘的页面文档作为一个文档集合。这样对于文档集合 d =
中的任一文档
,采用向量空间模型表示为:
=

其中m 为文档
特征向量的个数,
为文档
的第i个特征向量,
为文档
中
的权值。
2.2 页面相似度函数
采用向量空间模型表示的数据,必须选择计算两个特征矢量之间相似性的相似度函数。现在常用的方法有欧几里德距离、曼哈坦距离和夹角余弦函数。我们在这里采用夹角余弦函数。但是在计算时可能会遇到用于比较的两个特征矢量长度不一样,我们可以采用添零补齐的方法使两者长度一致。夹角余弦函数如下:
其中,c(x,y)表示页面x与y的相似度,
与
表示x与y对应的特征词的权值。页面x与y值越相似,c(x,y)值越大;反之则越小。
3 基于浏览行为的用户兴趣分析
研究表明,用户很多浏览行为都能很好地反映用户的兴趣。文献[6]指出用户的很多动作都能暗示用户的喜好,如查询、浏览页面和文章、标记书签、反馈信息、点击鼠标、拖动滚动条、前进、后退等。文献[7]的研究指出用户访问时的停留时问、访问次数、保存、编辑、修改等动作能够揭示用户兴趣。这些行为究竟怎样反映用户的兴趣,我们需要对其进行量化估算。
3 .1 浏览行为的分类
从表面上看能揭示用户对网页p兴趣度d(p)的浏览行为很多,但我们分析发现,起关键作用的是两种行为:在网页p上的浏览时间t(p)(简称t行为)和翻页/拉动滚动条的次数v(p)(简称v行为)。 原因有三:1)查询、编辑、修改等行为必定增加网页浏览时间和翻页次数,因此能够通过后者间接的得到反映。2)执行了保存、标记书签等动作的页面,若真为用户关心,通常以后会被多次调出来重新浏览,故可体现为访问次数。3)点击鼠标动作不被考虑,因为简单动作不能有效揭示用户兴趣。
3 .2 浏览行为参数的计算
为了找到t,v与网页兴趣度的定量关系,通过分析和实验,决定采用一元线性回归方法作为网页兴趣建模分析的工具。线性回归分析方法是在分析研究对象变化趋势的基础上建立函数模型,从而研究对象之间存在的相互依存关系。
用户浏览行为和网页兴趣度之间的回归方程可建立为: d(p)=a*t+b*v+c,其中,a,b,c是与t(p)和v(p)无关的未知参数,它们的估计可采用最小二乘法。这样通过该方程就可以计算用户对每个网页的行为兴趣度 bi (behavior interesting)。
4 用户兴趣模型的表示
4.1 内容分析和行为分析的结合
我们用得到的用户浏览的n张网页组成一个矩阵,每张网页表示为:

=
这样,用户浏览网页的特征矩阵就可表示为:
的每个行向量表示的是网页
,下标m=max (
)。
这样的表示在一定程度上代表了用户的兴趣,但也仅仅表示的是网页内容给用户带来的兴趣,真正反应用户兴趣的还应加上用户的行为兴趣数据.在矩阵d上加上用户的行为数据。将用户浏览的页面内容分析和用户的行为分析结合起来,就得到了完整的用户兴趣度模型。这样,改进后的用户的兴趣浓度就可表示为:
=
* bi。
4.2 用户兴趣的聚类及表示
聚类就是将数据对象分组成为多个类或簇,在同一簇中的对象之间具有较高的相似度,不同类中的对象差别较大。我们将层次聚类算法和 k-means 聚类算法相结合起来,利用层次聚类算法来产生 k-means 聚类算法所需的k值和初始聚类中心。这样大大提高了k-means 聚类算法的性能,能更准确地发现用户的兴趣所在。改进的 k-means 二次聚类算法描述如下:
输入:包含 n 张页面的特征向量表示矩阵c;
输出:一个已经分好类的用户兴趣树t;
算法:
1) 将c作为兴趣树的一个最大类,令t=c;
2) c作为一个类;
3) m = m+1;
4) 特征向量矩阵c中的每一行对象
(即每张页面文档)看作是一个具有单个成员的类
,这些类构成了d的一个聚类c =
;
5) 计算c中每对类
之间的相似度 sim
;
6) 设定一阀值
,选取具有最大相似度的类对值,如果max≤
,将
和
合并为一个新的类
,从而构成了d的一个新的聚类c=
,重复步骤(5),(6);如果max>
,凝聚算法结束,得到分为k个子类的聚类c =
;
7) 将 k 和c = {c1,c2,...,ck }分别作为 k-means 聚类要生成的簇的数目参数和初始聚类中心,执行 k-means 聚类,得到修正后的k个类
;
8) 把k个类的
作为初始类的子类;
9) 对于每一个

,令
, 如果δ<θ(θ为给定的一个接近于1的数),令c=
,转向2) ;否则不对
做任何处理;
10) 输出t,即是所得的用户兴趣分类树。
通过采用上述的综合聚类算法,即层次聚类算法和k-means 聚类算法相结合的算法,对这些网页进行聚类,就得到用兴趣分类树表示的用户兴趣模型。这样就得到了较为精简的用户兴趣模型。
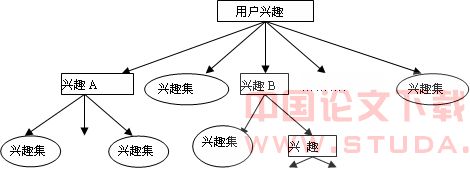
用户兴趣模型树可表示为如下结构:
5 结束语
随着internet的发展,个性化服务技术显的愈发重要。用户兴趣模型建立的准确与否,直接决定着个性化服务质量的好坏。本文通过对用户浏览的web页面进行兴趣度分析和对用户浏览行为分析相结合,得到用兴趣分类树表示的用户兴趣模型。由于采用的是隐式创建用户描述文件的方法,减少了因用户参于而带来的系统噪声,保证了所创建的用户兴趣模型的准确性。
参考文献
[1] 丁 浩,林 云. internet 上的个性化信息服务.中国计算机报. 2000.3.
[2] 曾 春,刑春晓,周立柱. 个性化服务技术综述[j].软件学报. vol.13,no.10,2002.
[3] 唐 倩,张 前,陈泓婕. 基于web的文本挖掘[j].计算机工程与应用,2002,21.
[4] 鲁 松,白 硕. 文本中词语权重计算方法的改进[j].2000 international conference on multilingual information processing, 2000:31-36.
[5] 高晓琴,蒋朝学,涂 瑞. web使用挖掘研究.微计算机信息,2006,21.
[6] 史忠植 著,知识发现. 清华大学出版社.2002.
[7] 谭 琼,李晓黎,史忠植. 一种实现搜索引擎个性化服务的方法[j]. 计算机科学, 2002,29(1):23-25.