[摘要]随着存储媒体容量和传输带宽的不断提高,高质量多声道数字音频系统也逐渐取代传统的单声道、立
体声系统,而成为新的传播媒体方式。本文着重介绍当前几种典型的多声道数字音频系统的编、解码技术。
以mpeg-2、ac-3、dts、mpeg aac多声道数字音频系统来讨论它们各自声道的配置、数据容量、数据率等所
带来的优缺点,最后介绍在数字音视频广播中,多声道数字音频系统的应用。
1、前言
对于cd格式来说,大家都知道它具有良好的信噪比、超过80db以上的动态范围以及超过15khz的频率范围,这
使得它具有良好的音频质量和满意的收听效果,但是它仅仅提供了两个声道。多声道数字音频系统通过声道
的扩展,不仅在质量上与cd音频不相上下,同时还带给听众身临其境的感受,而这是传统单声道和立体声无
法实现的,因此多声道数字音频系统已被更多的听众接受,同时也逐渐成为音乐制作的主流。
在众多的国际标准中,如smpte、ebu、itu-r、iso/iec、mpeg等,都涵盖着一种称之为5.1声道的多声道数
字音频格式。在即将制定的dvd-audio标准中,也规定将采用24bit采样精度、88.2,96,192khz采样率的多
声道数字音频格式。
一种广泛接受的多声道数字音频系统配置方案就是我们常称的5.1声道系统,也就是3/2/.1的配置方案。这
种方法是按照itr-u的建议bs.775来确定用于重放的扬声器摆放位置的,如图1所示。Www.11665.cOM
根据建议可知,5个全频带的重放扬声器分为前置扬声器(包括l、r、c)和后置扬声器(也称环绕扬声器,
包括ls、rs),按照图示所规定的角度和方位进行摆放,并且它们都位于一个圆的边界上,其中l、r扬声器
与c扬声器分别呈30度夹角,ls、rs扬声器与c扬声器分别呈110度夹角。除此5个全频带的声道外,还有一个
低频增强声道,称之为lfe,它的频率范围在200hz以下,大约是全频带倍频程的10%左右,因此也称点一声
道。它的放置没有特殊的要求,一般放置在前面。
5个重放扬声器的摆放并不是说能够完全重现真实的空间声像,其实5个扬声器的使用仅仅是一种重现空间声
像而采用的粗略的实现方式。当然,一方面重放的效果取决于音频素材的制作,另一方面则需要严格的重放
扬声器的空间位置摆放和收听者的位置关系。在电影院里我们往往能够感受到声像定位准确的音频效果,现
在也有一些提法,认为8个、10个、12个甚至更多的重放扬声器会有更加完美的音频效果。这些观点有它存在
的理由,声像的表现当然是越准确越好,但是一味的通过增加重放扬声器的数量以及增加音频声道数的话,
它也会带来另外的负面影响,如声像的定位更加困难等等,因此我们在此仅仅通过5.1声道的实现方式来进
行阐述。另外,我们还应明确一点,对于家庭消费者来说,5.1声道已经足够表现较完美的音频效果了。
不管是那种摆放方式,它的实现都离不开基本的编码方式和主要规则。另外5.1声道方式还会带来较大的压
缩比和较低的比特率(相对于更多声道的情况),下面就详细的来介绍一下多声道数字音频系统的编码方式。

图1 itr-u的建议bs.775确定的用于重放的扬声器摆放位置
1、多声道数字音频的编码
从立体声向多声道的过渡,增加了对存储和传输媒体的需要。下面以cd格式为例,假设它的采样频率为
fs=44.1khz,采样精度r为16bit,那么cd格式的音频数据率b为:
bcd=2×r×fs=1.411mb/s
由此可知,一个小时的cd格式的音乐需要635mb的存贮空间,其实cd最长的重放时间为74分钟。那么如果使
用的是多声道时,此时的数据率为:
bcdmultichannel=5.1×r×fs=3.598mb/s
同样一个小时的多声道格式的音乐需要1.62gb的存储空间,远远大于cd的容量。同时当前已应用的多
声道系统面临着带宽的问题。如美国的数字电视中仅仅给多声道的音频384kb/s的带宽,在internet音频广
播中,也只有56kb/s的数据通道,因此由上可知,多声道数字音频系统面临者存储容量和传输带宽的限制。
如何将多声道数字音频数据率降低的同时又能够保证音频质量,是多声道数字音频系统面临的重大问题。众
所周知,对于线性pcm来说,它的实现简单,在高容量/高带宽的前提下可以提供cd质量的音频信号。从另一
个角度来看,采样精度的提高以及采样频率的提高,会带来更高的音频质量,如将采样精度由r=16提高到
r=24;将采样频率由fs=44.1khz或fs=48khz提高到fs=96khz或fs=192khz。这种发展趋势已经逐渐地由一些
录音工程师和音乐制作商所接受,同样多声道数字音频系统则也要顺应这种趋势。但如果仍然采用线性pc
m,这无疑是增加了更大的数据量,提高了现有的数据率。
我们知道线性pcm并没有充分利用音频信号的特性进行编码,在pcm数据流中存在着大量的冗余信息。同时
要强调的是不管音频信号如何编解码、传输,最终还是要靠我们的人耳来实现的,如图2所示,因此我们
可以充分地考虑人耳的听觉特性,并加以利用,如人耳的掩蔽效应、哈斯效应等等。这样就可以将音频信
号中与人耳有关的那部分冗余信息去除掉,在编码时则仅仅对有用的那部分音频信号进行编码,从而降低
了参与编码的数据量。同时再将编码的信号进行比特精度的分配,对于幅度比较大的信号或变化比较快的信号分配更多的比特数,而对于幅度小、变化慢的信号则减少比特数的分配,从而达到减少数据率的可能性,实现编码的高效率。当然这种结果是以编码过程复杂化为代价的。下面具体分析几种声学模型。
图2 编码、传输、人耳听音的实现
2.1 根据听觉域度对可闻信号进行编码
人耳对声振动的感受,在频率及声压级方面都有一定的范围,频率范围正常人约为20hz~20khz,而声压级范围则是如图听阈曲线来描述的。意即在这条曲线之下的对应频率的信号是听不到的。

图16 mpeg-2音频混合后环绕声兼容性 如图3所示,对于信号a来说,由于其声压级超过听阈曲线的声压级域值,所以可以对人耳造成声振动的感
受,意即听到a信号。而对b信号来说,其声压级位于听阈曲线之下,虽然它是客观存在的,但人耳是不可闻
的。因此,可以将类似的信号去除掉,以减少音频数据率。
2.2 根据掩蔽效应,只对幅度强的掩蔽信号进行编码
人耳能在寂静的环境中分辨出轻微的声音,但在嘈杂的环境中,同样的这些声音则被嘈杂声淹没而听不
到了。这种由于一个声音的存在而使另一个声音要提高声压级才能被听到的现象称为听觉掩蔽效应。

如图4所示,虽然b、c两信号的声压级已超过听阈曲线的范围,人耳已可以听到b、c两信号的存在,但是由
于a信号的存在,通过前向掩蔽将c信号淹没掉,通过后向掩蔽将b信号淹没掉,从而最终到达人耳引起感觉
的只有a信号。因此,可以将类似的b、c信号去除掉以减少音频数据率。
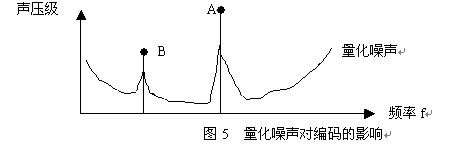
2.3 量化噪声使得不必全部编码原始信号
类似于人耳的听阈曲线,由于数字信号存在着量化噪声,如图5所示,对于信号a和b来说,并不一定要将a、
b信号进行全部幅度的编码,而只需将a、b信号与量化噪声的差值进行编码就可以达到相同的听觉效果,因
此,在编码过程中实际量化幅度就可以大大的减少,而减少数据率。
2.4 通过子带分割来进行优化、编码
在传统的编码过程中,都是将整个频带作为操作对象,采用相同的比特分配对每个信号进行量化。而实际
上,由于听觉曲线的存在及其它因素,对于幅度较小的信号可以分配较少的比特数就可以达到要求,因此
将整个频带分成多个子频带,然后对每个子频带的信号独立编码,从而使得在每个子频带中比特分配可以
根据信号自身来适应。

如图abcd四个信号,如果对整个频带编码,对于d信号来说分配16比特来量化则显得多余浪费,所以如果
将abcd分别置于不同的子带内,则可在分别所处的子带内使用最适合的比特数分配给信号来编码,从而减
少数据率,同时如果用于分割的子带分辨率越高,意即子带的频带相对越窄,那么在子带中分配的比特数
就越精确,而减少了比特率。
2.5 不同的实现方式
当前在数字音频编码领域存在着各种不同的编码方案和实现方式,为了能够让大家对此有一个较完整的认
识,在本文中仅对当前流行的几种典型的编码方法做一个介绍。不管是通过那一种方式实现,其基本的编
码思路方框图都大同小异,如图7所示。对于每一个音频声道中的pcm音频信号来说,首先都要将它们映射
到频域中,这种时域到频域的映射可以通过子带滤波器(如mpeg layers i,ii,dts)或通过变换滤波器
组(如ac-3,mpeg aac)实现。这两种方式的最大不同之处在于滤波器组中的频率分辨率的不同。

每个声道中的音频采样块首先要根据心理声学模型来计算掩蔽门限值,然后由计算出的掩蔽门限值来决定
如何将公用比特区中的比特分配给不同的频率范围内的信号,如mpeg layers i,ii,dts所采用;或由计
算出的掩蔽门限值来决定哪些频率范围内的量化噪声可以引入而不需要去除,如ac-3,mpeg aac所采用。
然后根据音频信号的时域表达式进行量化,随后采用静噪编码(如mpeg layers i,ii,dts,mpeg aac)。
最后,将控制参数及辅助数据进行交织产生编码后的数据流。解码过程则首先将编码后的数据流进行解复
用,然后通过比特流中传输的控制参数对音频数据反量化,或通过心理声学模型参数反向运算得到音频信
号(如ac-3),最后将得到的音频信号由频域反变换到时域,完成解码过程。
另外多声道数字音频编码技术还充分利用了声道之间的相关性及双耳听觉效应,来进一步去除声道之间的
冗余度和不相关度。去除通道之间的相关度,一种最常用的方法是m/s方式,在这种方式中是将两个独立
声道的频谱相加和相减,根据两个声道的相关度大小,来决定是传输和/差信号还是传输原始信号。
由于人耳对于频率超过2-3khz的声音定位主要是通过内耳密度差分(iid)实现的,因此为了进一步减少
数据率,将各个声道中频率超过约定门限值的信号组合后再进行传输。这种技术应用在mpeg layers i,
ii,iii中,实现强度立体声编码;用在ac-3中对两个声道或耦合声道实现多声道编码。在mpeg aac中,
则既可实现强度立体声编码,又可实现多声道编码。
1、杜比数字ac-3编解码压缩过程
ac-3最早是在1991年的电影“batman returns”中应用的。它的应用不仅在电影界占有一席之地,而且
它已被北美地区的数字电视及dvd视频定为其数字音频实施规范。我们熟知的ac-2,ac-3都是由两声道发
展而来的,即杜比数字(dolby digital)。对于数字音频信号来说,通过应用数字压缩算法,来减少正
确再现原始脉冲编码调制(pcm)样本所需要的数字信息量,得出原始信号经数字压缩后的表达式。
3.1 ac-3编码过程
ac-3编码器接受pcm音频并产生相应的ac-3数码流。在编码时,ac-3算法通过对音频信号的频域表达式进
行粗量化,达到高的编码增益(输入码率对输出码率之比)。如图8所示。
编码过程的第一步是把音频表达式从一个pcm时间样本的序列变换为一个频率系数样本块的序列。这在分
析滤波器中完成。512个时间样本的相互重叠样本块被乘以时间窗而变换到频域。由于相互重叠的样本
块,每个pcm输入样本将表达在两个相继的变换样本块中。频域表达式则可以二取一,使每个样本块包含
256个频率系数。这些单独的频率系数用二进制指数记数法表达为一个二进制指数和一个尾数。这个指数
的集合被编码为信号频谱的粗略表达式,称作频谱包络。核心的比特指派例行程序用这个频谱包络,确
定每个单独尾数需要用多少比特进行编码。将频谱包络和6个音频样本块粗略量化的尾数,格式化成一个
ac-3数据帧(frame)。ac-3数码流是一个ac-3数据帧的序列。

在实际的ac-3编码器中,还包括下述功能:
l附有一个数据帧的信头(header),其中包含与编码的数码流同步及把它解码的信息(比特
率、取样率、编码的信道数目等)。
l插入误码检测码字,以便解码器能检验接收的数据帧是否有误码。
l可以动态的改变分析滤波器组的频谱分辨率,以便同每个音频样本块的时域/频域特性匹配的
更好。
l频谱包络可以用可变的时间/频率分辨率进行编码。
l可以实行更复杂的比特指派,并修改核心比特分派例行程序的一些参数,以便产生更加优化
的比特指派。
l一些声道在高频可以耦合在一起,以便工作在较低比特率时,可得到更高的编码增益。
l在两声道模式中,可以有选择的实行重新设置矩阵的过程,以便提供附加的编码增益,以及
当两信道的信号解码时使用一个矩阵环绕声解码器,还能获得改进的结果。
3. 2 ac-3解码过程
解码过程基本上是编码的逆过程。解码器必须同编码数码流同步,检查误码,以及将不同类型的数据
(例如编码的频谱包络和量化的尾数)进行解格式化。运行比特指派例行程序,将其结果用于解数据
大包(unpack)和尾数的解量化。将频谱包络进行解码而产生各个指数。各个指数和尾数被变换回到
时域成为解码的pcm时间样本。如图9所示:

图9 ac-3解码过程框图
在实际的ac-3解码器中,还包括下述功能:
l假若检测出一个数据误码,可以使用误码掩盖或静噪。
l高频内容耦合在一起的那些声道必须去除耦合。
l无论何时已被重新设置矩阵的声道,必须进行去除矩阵化的过程(在2-声道模式中)。
l必须动态的改变综合滤波器组的分辨率,与编码器分析滤波器组在编码过程中所用的方法
相同。
3. 3 杜比数字ac-3编码数据格式
经过杜比数字ac-3编码器的编码处理,可以将原始的数据pcm信号编码为杜比数字ac-3音频数据流。
一个ac-3串行编码的音频数据流是由一个同步帧的序列所组成。如图10所示。
由图可见,每个同步帧包含六个编码的音频样本块(ab)其中每个代表256个新的音频样本。在
每个同步帧开始的同步信息(si)的信头中,包含为了获得同步和维持同步所需要的信息。接着si后
面的是数码流信息(bsi)的信头;它包含描述编码数据流业务的各种参数。编码的音频样本块之后接
着是一个辅助数据(aux)字段。在每个同步帧结尾处是误码检验字段,其中包含一个用于误码检测的
crc字。一个附加的crc字位于si信头中,以供选用。
ab0~ab5的每一块代表一个编码通道,可以被分别独立解码,块的大小可以调整,但总数据量不变。在
图中还有两个未标出的crc,其中第一个位于帧的5/8处,另一个位于帧未。之所以如此安排,目的就
是可以减少解码器的ram需求量,使得解码器不必完全接收一帧后才解码音频数据,而是分成了两部
分进行解码。
3.4 杜比数字ac-3的兼容性
由于ac-3比特流中同步结构中的ab0~ab5是独立解码的,因此可以将这些编码信号重新构造为所需的输
出信号,即输出的下行兼容性。如图11所示。

图11 ac-3输出的下行兼容性
在许多重放系统中,扬声器的数目不能同编码的音频声道的数目匹配。为了重现完整的音频节目
需要向下混合。在帧同步中,ab0~ab5中记录着六个独立声道的音频数据,按照ac-3重放时的安排,
我们称之为l、r、c、ls、rs、lfe。一般用于向下混合的过程中,低音增强lfe通道记录的音频信号
主要用于渲染烘托气氛,所以向下混合时,只用其中的l、r、c、ls、rs。从图中可以看到编码后的
ac-3数据流可以直接传输后经解码器解码为5.1通道音频信息进行重放,也可以向下混合为两个声道
信号,然后经不同的解码器得到不同的重放模式。就单一环绕声道(n/1模式)而言,把s称为单个
环绕声道。从图中可看出,向下混合提供两种类型:向下混合为lt、rt矩阵环绕编码的立体声对;
向下混合为通常的立体声信号lo、ro。向下混合的立体声信号(lo、ro或lt、rt)可进一步向下混
合为单声道m,通过两个声道简单的相加即可。如果将lt、rt向下混合为单声道,环绕信息将会丢
失。当希望需要一个单声道信号时则lo、ro向下混合更可取。
用于lo、ro立体声信号的一般3/2向下混合方程式为:
lo=1.0′l+clev′c+slev′ls;
ro=1.0′r+clev′c+slev′rs;
如果接着lo、ro被组合成单声道信号重放,有效的向下混合方程式为:
m=1.0′l+2.0′clev′c+1.0′r+slev′ls+slev′rs;
如果只出现单个环绕声道s(3/1模式),则向下混合方程式为:
lo=1.0′l+clev′c+0.7′slev′s;
ro=1.0′r+clev′c+0.7′slev′s;
m=1.0′l+2.0′clev′c+1.0′r+1.4′slev′s;
其中clev、slev分别代表中央声道混合声级系数和环绕声道混合声级系数,在bsi数据中由
cmixlev、surmixlev比特字段来指出相对应的值。
用于lt、rt立体声信号的一般3/2向下混合方程式为:
lt=1.0′l+0.707′c-0.707′ls-0.707′rs;
rt=1.0′r+0.707′c+0.707′ls+0.707′rs;
如果只出现单个环绕声道s(3/1模式),则向下混合方程式为:
lt=1.0′l+0.707′c-0.707′s;
rt=1.0′r+0.707′c+0.707′s;
经过对独立声道的音频信号进行不同的分配及矩阵重组,则实现了ac-3数据流的向下兼容性,
意即通过不同的解码器、解码矩阵方式,可以得到杜比数字5.1声道环绕声、立体声、杜比
prologic、单声道以及杜比的虚拟环绕声方式。其中lo、ro与lt、rt的最大区别就是lt、rt是
记
录的全部的l、r、环绕声的信息,经过矩阵重解可得到环绕声信息,而lo、ro则是将环绕声信
息增加支立体声信号中,无法再重现环绕声信号信息。
4、mpeg-2多声道编解码过程
mpeg-2感知编码系统充分利用了心理声学中的掩蔽效应和哈斯效应,利用压缩编码技术,将原始
音频信号中不相关分量和冗余分量有效的去除掉,在不影响人耳听觉阈度和听音效果质量上,将
音频信号压缩。
4.1 mpeg音频子带编码器的基本结构
感知型子带音频编码器不断地对音频输入信号进行分析。由一个心理声学模型动态地确定掩蔽门限,
即在该掩蔽门限之下的多余的噪声是无法为人的听觉系统听到的。由该心理声学模型产生的信息被
馈至一个比特分配模块,该模块的任务是将各声道可用的比特以一种优化的方式在频谱范围内进行
分配。输入信号还与上述过程并行地被分割到一系列称为子带的频带中。每个子带信号都在经过定
标处理后被重新进行量化,该量化编码过程引入的量化噪声不能超过已确定的对应子带的掩蔽门限。
因此量化噪声频谱就与信号频谱进行了动态自适应。“比例因子”和各子带所使用的量化器的相关
信息与编码后的子带样值一同进行传输。
解码器可以在不了解编码器如何确定编码所需信息的情况下对码流进行解码。这可以降低解码器的
复杂度,并为编码器的选择和解码器开发提供了很大的灵活性。如在心理声学研究上取得了新的结
果,则更高效率和更高性能的编码器可在与所有现有解码器完全兼容的条件下得以应用。这一灵活
性目前已有了成功的例子,现在最高技术水平的编码器的性能已超过了标准化过程中使用的早期编
码器。如图12所示。

图12(a)mpeg音频编码器框图
4.2 层
mpeg音频标准包括了三种不同的算法,称为层。层数越高,相应可达到的压缩比就越高,而复杂度、
延时及对传输误码的敏感度也越高。层ii专门对广播应用进行了优化。它使用了具有32个等宽子带划
分的子带滤波,自适应比特分配和块压扩。单声道的码率范围为32-192 kbps,立体声为64-384 kbps。
它在256 kbps及192 kbps相关立体声条件下的表现十分出色。128 kbps(立体声)条件下的性能在许
多应用中仍可接受。
4.3 mpeg-2在多声道音频方面的扩展
itu-r工作组tg10-1在关于多声道声音系统的建议方面进行了工作。该项工作的主要成果就是建议
bs.775,其中说明一个适当的多声道声音配置应包含五个声道,分别代表左、中央、右、左环绕、右
环绕声道。如果使用了一个作为选项的低频增强声道(lfe),则该配置被称为“5.1”。五声道配置
也可表示为‘3/2’,即三个前置声道及两个环绕(后置)声道。
mpeg已认识到应根据itu-r建议775来增加音频标准的多声道能力的必要性。
这是在第二阶段完成的,由此产生了mpeg-2音频标准。在多声道声音方面的扩展支持在一路码流中传
输五个输入声道、低频增强声道以及7个旁白声道。该扩展与mpeg-1保持前向及后向兼容。前向兼容性
意味着多声道解码器可正确地对立体声码流进行解码。后向兼容性则意味着一个标准的立体声解码器
在对多声道码流进行解码时可输出兼容的立体声信号。
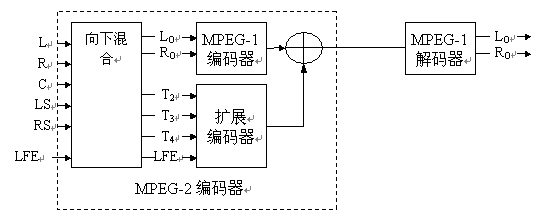
这是通过一种真正的可分级方式实现的。在编码器端,五个输入声道被向下混合为一路兼容立体声信
号。该兼容立体声信号按照mpeg-1标准进行编码。所有用于在解码器端恢复原来的五个声道的信息都
被置于mpeg-1的附加数据区内,该数据区被mpeg-1解码器忽略。这些附加的信息在信息声道t2、t3及
t4以及lfe声道中传输,这几个信息声道通常包含中央、左环绕和右环绕声道。mpeg-2多声道解码器不
但对码流中的mpeg-1部分进行解码,还对附加信息声道t2、t3、t4及lfe解码。根据这些信息,它可
以恢复原来的5.1声道声音。如图13所示。

13 mpeg-2编码器/解码器框图
当相同码流馈送至mpeg-1解码器时,解码器将只对码流的mpeg-1部分进行解码,而忽略所有附加的多
声道信息。由此它将输出在mpeg-2编码器中经向下混合产生的两个声道。这种方式实现了与现有的双
声道解码器的兼容性。也许更为重要的是,这种可分级的方式使得即使在多声道业务中仍可使用低成
本的双声道解码器。考虑到所使用的其它所有编码策略,多声道业务中的双声道解码器本质上就是一
个对所有声道进行解码并在解码器中产生双声道向下混合信号的多声道解码器。如图14所示。
就其包含了不同的可由编码器使用以进一步提高音频质量的技术而言,该标准是具有很大灵活性的。
4.4 定向逻辑兼容性
如果源素材已经经过环绕声编码(如dolby环绕声),广播业者可能希望将它直接播送给听众。一种
选择是将该素材直接以2/0(仅为立体声)模式播送。环绕声编码器主要是将中央声道信号分别与左
右声道信号同相相加,而将环绕声道信号分别与左右声道信号反相相加。为能对这些信息正确解码,
编解码器必须保持左右声道彼此之间的幅度和相位关系。这在mpeg编码中是通过限制强度立体声编码
只能在高于8khz的频率范围内使用而得以保障的,因为环绕声编码仅在低于7khz的范围内使用环绕声
道信息。如图15所示。

图15 使用mpeg-1音频播送环绕声素材
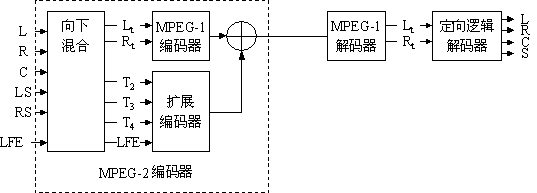
当传输多声道信息时,与现有(专利的)环绕声解码器的兼容性可通过几种手段得以实现。多声
道编码器在工作时使用一个环绕声兼容的矩阵。这可以使立体声解码器能够接收环绕声编码的信号,
并可选择将其传送给环绕声解码器。一个完整的多声道解码器将对所有信号进行再变换,以获得原来
的多声道表现。mpeg-2多声道语法支持这种模式,进而也为dvb规范所支持。如图16所示。
4.5 mpeg-2在低采样率方面的扩展
除了在多声道方面的扩展外,mpeg-2音频还包含了mpeg-1音频在低采样率方面的扩展。该扩展的目的
是以一种简单的方式获得改进的频谱分辨率。通过将采样率减半,频率分辨率就提高了两倍,但时间
分辨率则劣化了两倍。这可使许多稳态信号获得更好的质量,而对一些在时间特性上要求严格的信号
而言质量则下降了。半采样率的使用是在码流中通过将每帧帧头中的某一比特,即id位置设为“0”
来表示的。而且,可用码率表也进行了修改,以便在低码率条件下提供更多的选择,每个子带可用的
量化器也为适应更高的频率分辨率作了修改。
5、先进音频编码(advanced audio coding-aac)
mpeg aac(先进音频编码)是于1997年成为iso/iec标准的(参见iso/iec 13818)。aac是以新建立
的mpeg-4标准中的时域到频域映射的编码算法组成的。aac从提高效率的角度出发,放弃了与原
mpeg-1解码器的后向兼容性,这也是该算法在开始时被称为nbc的原因。
5.1 aac的主要特点
aac可以支持1到48路之间任意数目的音频声道组合、包括15路低频效果声道、配音/多语声声道,以
及15路数据。它可同时传送16套节目,每套节目的音频及数据结构可任意规定。在码率为64kbps/声
道的条件下,aac可以提供很高的声音质量。
根据不同的应用场合,aac提供了三种类型(profile)以供选择,即主要类型(main profile)、
低复杂度类型(low complexity profile)、可放缩采样率类型(scaleable sampling rate, ssr
profile)。因而其可应用范围很广。
5.2 aac算法结构
为提高音频编码效率,aac采用了许多先进技术,如霍夫曼编码、相关立体声、声道耦合、反向自适
应预测、时域噪声整形、修正离散余弦变换(mdct)、及混合滤波器组等。其算法基本结构框图如图17所示。

其中,滤波器组与mpeg层iii所采用的滤波器组相比,由于层iii算法在对滤波器进行选择时考虑了兼
容性问题,因而具有固有的结构上的不足;而aac则直接采用了mdct变换滤波。同时,aac增加了窗口
长度,由1152点增至2048,使mdct的性能优于原来的滤波器组。
时域噪声整形(tns)技术是时域/频域编码中一项新颖的技术。它利用频域的自适应预测的结果来对
时域中量化噪声的分布进行整形处理。通过采用tns技术,可以使特殊环境下的话音信号质量得到显著
的提高。
后向自适应预测是一项在语音信号编码系统领域建立起来的技术。它主要利用了某一特定形式的音频
信号易于预测的特点。
在量化过程中,通过对量化精度更为精细的控制,可以使给定的码率得到更加有效的利用。
在码流复接时,通过对必须传输的信息进行熵编码使冗余度降至最低。
通过以上各种编码技术的运用以及采用一种可变的码流结构,使aac编码算法在得到大大优化的同时,
也为将来进一步提高编码效率提供了可能性。
事实上,在aac编码的三种类型中,各种编码技术的使用也是不同的,也就是说,三种类型的算法复杂
度是不同的。这一不同考虑了编、解码两端的算法复杂度。例如,后向自适应预测约占解码运算量的
45%左右,在lc和ssr类型中都没有采用这一技术。另外,在lc类型中,tns滤波器的长度被限制为12个
系数,但仍保持了18 khz带宽;在ssr类型中,tns也只使用12个系数,并且带宽限制为6 khz,同时该
类型也没有采用声道耦合技术,在混合滤波器组的结构及增益控制方面也与另两种类型不同。
aac可以在低数据率的情况下提供较高质量的音频信息,如每个声道仅64kb/s时就会有比较好的性能。
aac当前的应用主要用于日本的数字音频广播及美国的iboc(带内同频技术)。
6、 用于dts的相干声学编码
dts系统中采用的数字音频压缩算法――相干声学编码,主要目的就是用于提高民用音频重放设备重放
的音频质量的,其音频重放质量可以超越原有的如cd唱片的质量。同时通过更多扬声器的使用,使得
听众可以感受到普通立体声无法达到的声音效果。因此总体目标就是将听众真正的带入专业的音响领
域及多声道环绕声的天地。
相干声学编码器是一种感知、优化、差分子带音频编码器,它使用了多种技术对音频数据进行压缩。下
面将分别对其进行详细的描述。从整体来看,编码器与解码器的实现是不对称的。理论上编码器可以
设计的非常复杂,但实际上,编码器发展成为包括两种音频分析的模式。解码器与编码器相比则简单的
多,因为解码算法是根据编码数据流中的参数来控制的,解码器不需要做任何的计算来决定重放的音频
质量。
6.1编码过程
编码过程中的第一步是通过一个多相滤波器组将每个声道的全频带24比特线性pcm源信号进行分割到一定
数目的子带中去。这种滤波方式提供了一种框架,既可以消除频谱滚降较快的音频信号分量,同时又去除
了感知上的冗余度。多相滤波器只要通过低复杂度的计算就可以实现更好的线性、更高的理论编码增益和
更理想的阻带衰减。每一个子带信号都包含了相应的、严格限制带宽的线性pcm音频数据。子带的个数及
相应的带宽是由源信号的带宽来决定的,一般情况下分为32个独立的子带。

图18 相干声学编码器流程图
在每个子带中进行差分编码(子带adpcm),这一步可以去除信号中的客观冗余量,如周期很短的信号。
通过对信号的对比分析、心理声学及信号瞬态的分析可以判断信号中的感知冗余信息。通过子带范围比特
率的选择和上述分析的结果,来调整对每个信号的差分编码程序的执行。差分编码与心理声学模型(如噪
声掩蔽门限)的结合可以得到较高的编码效率,甚至可以在不影响主观听觉的基础上进一步降低比特率。
如果使用较高的比特率,那么对于心理声学模型的依赖性则相对较弱,但可以肯定随着比特率的增加,
编码信号的保真度也会提高。
比特指派程序管理着所有音频声道中子带信息的编码指派和分配。在时间和频率上的自适应可以优化音频
质量。作为音频编码系统设计的基础,比特指派程序通过对音频信号比特的分配和使用的比特率来决定音
频质量。通过在编码策略中独立的执行这些程序使得运算的复杂程度大大提高,但是这样做却可以使得解
码器相对的简单。相反,随着比特率的增加,比特指派程序的灵活性也将大大降低,但是可以确保音频质
量的透明性。
编码过程中最后一步就是将来自每个子带adpcm处理后的音频数据进行数据复用(或称打包)。数据复用
器将所有声道中子带数据加上附加的辅助信息进行打包,形成特殊数据语法格式的编码数据流。在数据流
中加入的同步信息将用于解码器对编码数据流的同步。
6.2
对编码数据流同步以后,首先就是对编码数据流进行解包,如果必要的话还将对编码数据流进行检错及误
码校正,然后将解包的音频数据送到相应声道的子带中去。
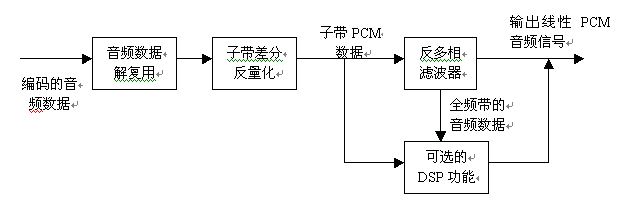
图19 相干声学解码器流程图
第二步是通过在每个子带中传输的辅助信息指令,对子带中的差分信号进行反量化得到子带pcm信号。这
些通过反量化得到的子带pcm信号再进行反滤波处理,得到每个声道的全频带的时域pcm信号。在解码器中,
没有程序用于音频质量的调整。
在解码器中包括一个可选的dsp功能模块,这个模块主要用于用户的编程使用。它允许对单个声道或全部
声道中子带或是全频带pcm信号进行处理。这些功能诸如上矩阵变换、下矩阵变换、动态范围控制以及声
道之间的延时调整等。
6.3
dts系统最早是用于电影应用中的。在1993年的电影“jurassic park”(侏罗纪公园)中,没有使用
ac-3,而是使用了dts多声道数字音频系统。dts系统中的音频数据是存储在一张cd-rom上的,取代了将声
音记录在胶片上的方式,而是在胶片上记录用于同步cd-rom音频信息的时间码,通过电影胶片上的时间码
来同步播放cd-rom。由于cd-rom与电影胶片磁迹相比,具有更大的容量和更稳定的可靠程度,因此它可以
在4:1压缩比的情况下提供质量更高的多声道音频信息。对于ac-3来说,典型的压缩比为12:1。随着应
用的普及,dts系统又提出一种低数据率版本,其参数规范如下:
音频声道的个数dts=1――10.1
fsdts=8――192khz
rdts=16――24bit
bdts=32――6144kb/s
数据帧大小dts=512样本
在低数据率版本中,由0到24khz的32个子带的频率,通过一个512抽头的多相正交镜象滤波器(pqmf)来
实现从时域到频域的映射。另外8个附加的子带覆盖了24khz到48khz之间频率范围,2个附加的子带覆盖了
48 khz到96 khz之间的频率范围。为了进一步减小冗余度,采用了前向自适应线性预测,同时心理声学模
型用来对信号进行预测,在量化过程中使用了标度量化和矢量量化。
dts的大多数应用都是采用相对较小的压缩比、工作在几乎无损情况的模式下的。一般来说,数据率在
1mb/s的情况下,dts可以提供较好质量的音频。dts的应用也主要是在电影、cd及dvd视频中。另外,dts
所具有的可变比特率编码方式使得它同样可以应用于dab及dvd的广播中。
7、
数字音频广播系统的发展是从85年以后开始的,其中包括了我们熟知的eureka 147 dab(尤里卡147数字
音频广播)和dvb。不断发展的数字调制方式及编码算法都为数字音频广播提供了更加有效的传输和存储
方式,使得在有限的带宽中以较低比特率来传输声道数更多、质量更优的音频信号成为可能。同样在数字
音频广播系统的发展中也充分利用了这些以此为核心的新技术。以前,立体声广播起着主导的作用,现在
随着越来越多的多声道数字音频系统的应用,在数字音频广播领域也已经开始接纳并制定相关的音频标准
了。在eureka 147 dab和dvb中,已经包括了多声道数字音频的扩展。
7.1
eureka 147 dab国际协议是于1986年由16个欧洲成员组织为制定数字音频广播标准而制定的标准规范。随
后又有一些新的组织机构加入到这项协议工作中去,并于1995年形成了第一个dab的标准。在同一年中,
世界范围的dab论坛也相继成立,它们的目标就是促进世界各地更多的组织机构采用以eureka 147 dab为
蓝本的数字音频广播的实现。
eureka 147 dab系统的设计是用来取代现行的fm广播业务的,它采用cofdm(编码正交频分复用)以便于
更好地进行移动接收和克服多径效应,载波采用dqpsk(差值正交相移键控)进行调制,通道编码采用卷
积编码,以满足可调整码率的需要。
eureka 147 dab系统使用1.536mhz的频谱带宽来传输最大不超过1.5mb/s的数据,因此对于多声道来说,
如为6个声道,则每个声道的数据率最大不超过256kb/s。对于声道如何分配及使用,则是根据节目数量/
数据业务与音频质量来折衷考虑的。由于早期的eureka 147 dab源编码的发展没有反映出当前最新发展的
技术,同时由于历史原因及dab标准由欧洲制定,而欧洲长期以来都采用的是mpeg技术,考虑到兼容等问
题,因此dab系统中音频编码系统采用的是mpeg layer ii编码方案。不能说mpeg layer ii编码方案有什么
不好,但是如果我们综观当前多声道数字音频系统的最新发展,不难看出,有更多更好的方案可以被采用,
如在提高声音质量上可采用dts系统,在增加声道数目上可采用mpeg aac系统。
7.2
dvb项目是在1993年由220多个世界组织来制定建立的。这些世界组织包括广播业者、制造商、网络管理者
和致力于发展数字电视标准的各种组织机构。最早的dvb业务是在欧洲开始的,现在dvb标准不仅是欧洲的
数字电视标准,而且它也扩展到亚洲、非洲、美洲及澳大利亚等地区,成为这些地区数字电视的选择标准
之一。与此不同的美国采用的是atsc系统。
在dvb的标准中规定了三个子系统:dvb-s(卫星)、dvb-c(有线)和dvb-t(地面)系统。dvb-s系统是
一种单载波系统,是最早实现的dvb标准,它是建立在正交相移键控(qpsk)调制和通道编码(卷积编码
和里得-所罗门块编码)的基础之上的,典型的码率为40mb/s左右。dvb-c系统是以dvb-s系统为基础建立
的,不同的是它采用qam(正交调幅)调制方式,取代了用于dvb-s中的qpsk调制方式。在dvb-c中如果使
用64点qam调制,则可以实现在8mhz的带宽中传输38.5mb/s的数据。dvb-t系统与以上两者都不同的是采用
了cofdm的调制方式,而通道编码则与前两者基本相同。在dvb-t系统中,可以实现在7mhz的带宽中传输
19.35mb/s的数据。
dvb系统的源编码是建立在mpeg-2视频和mpeg-2系统标准上的。同时在dvb中也提供了与立体声相兼容的多
声道数字音频系统。同样由于历史及其他一些原因,在dvb音频部分中仍然采用的是mpeg layer ii多声道
数字音频系统,在dvb的标准中也同时规定可以采用灵活性更大、质量更高,超过mpeg layer ii mc系统
的多声道数字音频系统作为dvb的音频部分。
总之,随着数字广播的不断发展,相信这些已经成熟的各种技术都将有它们各自的用武之地。
8、结语
在本文中,我们主要讨论了当前较流行、较成熟的几种多声道数字音频系统,同时也对它们所采用的编码
方法的主要技术做了详尽的分析比较。随着存储媒体及传输带宽技术的不断发展,相信多声道数字音频系
统会逐渐取代传统的如cd格式的音频系统;同样应用于多声道数字音频系统中的音频编码及传输方案也会
不断的进行更新、发展。更多声道的实现及更高质量的音频系统实现都会成为可能,如新建立的
dvd-audio音频技术中的编码方案已远远超越了pcm音频方式。
总而言之,我们相信在今后的数字广播的发展中,不管是dvb、dab、数字视频、音频广播,还是atsc数字
电视系统等,都将会采用不受带宽限制(相对而言)、可提供更高质量、更多声道的多声道数字音频系统。
参考文献
[1]itu-r recommendation bs.775-1,“multi-channel stereophonic sound system with and
without accompanying picture”,international telecommunication union,geneva,switzerland,
1992-1994
[2]itu-r recommendation bs.1116,“methods for the subjective assessment of small
impairments in audio systems including multi-channel sound system”,international
telecommunication union,geneva,switzerland,1992-1994
[3]j.d.johnson and ferreira,“sum-difference stereo transform coding,”ieee icassp
1992,pp.569-571。
[4]iso/iec 13818-3
[5]iso/iec 11172-3
[6]m.davis,“the ac-3 multi-channel coder ”,presented at the 95th aes convention, new
york, october 1993,preprint 3774.
[7]iso/iec 13818-7,adanced audio coding(aac)
[8]“dts coherent acoustics delivering high-quality multi-channel sound to the
consumer,”presented at the 100th aes convention, copenhagen, may 1996,present 4296